OA0 ›
代码 ›
SmolLM — 极致轻量的端侧大语言模型
SmolLM — 极致轻量的端侧大语言模型
integration · 2025-10-14 05:27:58 · 166 次点击 · 0 条评论Smol Models 🤏
欢迎来到 Smol Models,这是来自 Hugging Face 的高效轻量级 AI 模型家族。我们的使命是创建功能强大且完全开放的紧凑模型,涵盖文本和视觉领域,这些模型能够在设备上高效运行,同时保持强劲的性能。
[新] SmolLM3 (语言模型)
我们的 3B 模型性能超越了 Llama 3.2 3B 和 Qwen2.5 3B,同时与更大的 4B 替代模型(Qwen3 和 Gemma3)保持竞争力。除了性能数据,我们还分享了如何使用公开数据集和训练框架构建它的完整细节。
资源:
- SmolLM3-Base
- SmolLM3
- 博客文章
摘要:
- 3B 模型,基于 11T token 训练,在 3B 规模上达到 SOTA,并与 4B 模型竞争。
- 完全开放的模型,开放权重 + 完整的训练细节,包括公开的数据混合方案和训练配置。
- 指令调优模型,支持双模式推理(think/no_think 模式)。
- 支持 6 种语言:英语、法语、西班牙语、德语、意大利语和葡萄牙语。
- 支持 128k 长上下文,采用 NoPE 并使用 YaRN 方法。
👁️ SmolVLM (视觉语言模型)
SmolVLM 是我们紧凑的多模态模型,能够:
- 处理图像和文本,执行视觉问答、图像描述和视觉故事讲述等任务。
- 在单次对话中处理多张图像。
- 在设备上高效运行。
仓库结构
smollm/
├── text/ # 与 SmolLM3/2/1 相关的代码和资源
├── vision/ # 与 SmolVLM 相关的代码和资源
└── tools/ # 共享工具和推理工具
├── smol_tools/ # 轻量级 AI 工具
├── smollm_local_inference/
└── smolvlm_local_inference/
快速开始
SmolLM3
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "HuggingFaceTB/SmolLM3-3B"
device = "cuda" # 使用 GPU 或 "cpu" 使用 CPU
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
).to(device)
# 准备模型输入
prompt = "Give me a brief explanation of gravity in simple terms."
messages_think = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages_think,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 生成输出
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
# 获取并解码输出
output_ids = generated_ids[0][len(model_inputs.input_ids[0]) :]
print(tokenizer.decode(output_ids, skip_special_tokens=True))
SmolVLM
from transformers import AutoProcessor, AutoModelForVision2Seq
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
model = AutoModelForVision2Seq.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "What's in this image?"}
]
}
]
生态系统
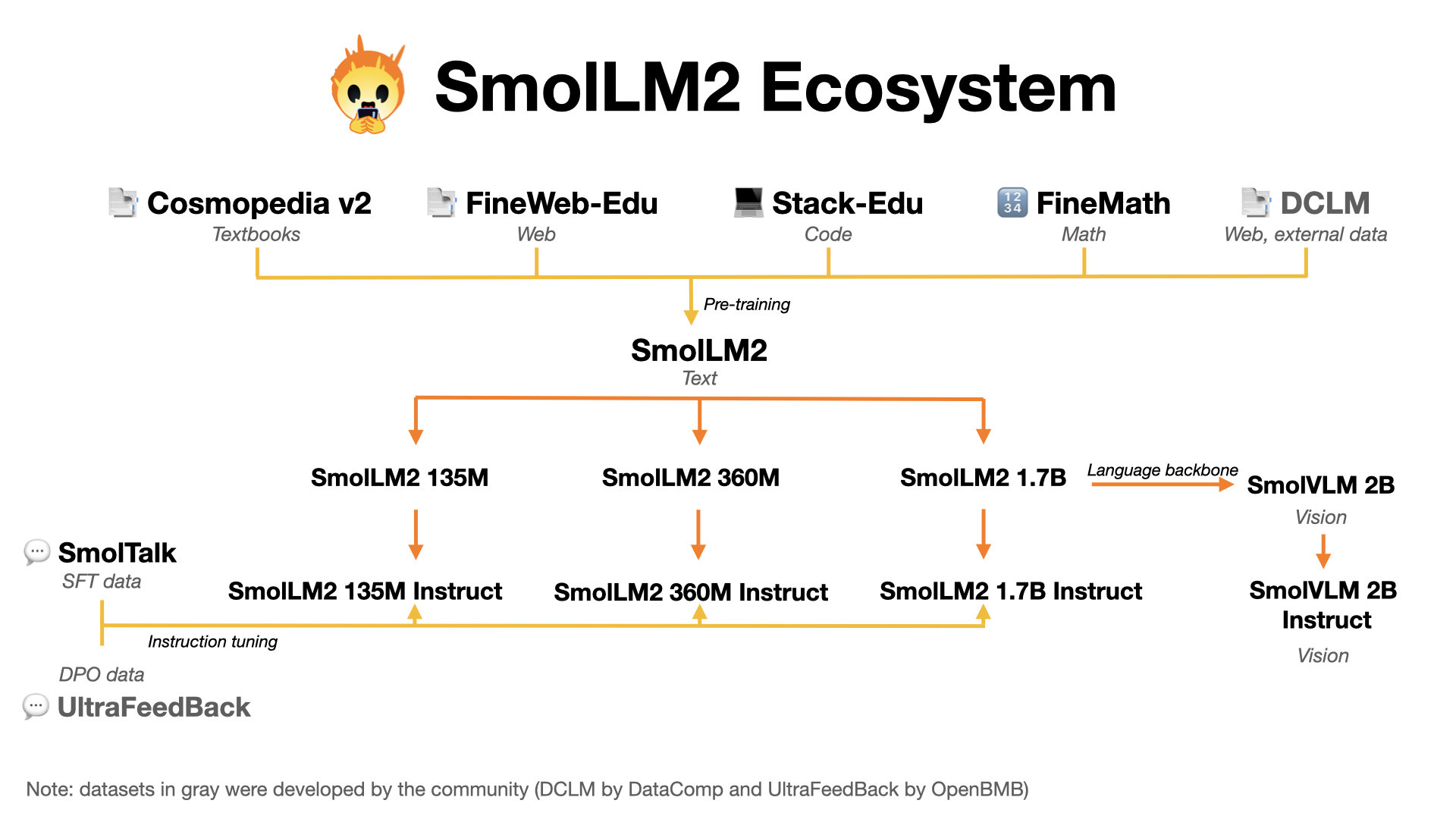
资源
文档
预训练模型
数据集
- SmolLM3 预训练数据集
- SmolTalk - 我们的指令调优数据集
- FineMath - 数学预训练数据集
- FineWeb-Edu - 教育内容预训练数据集