TensorRT LLM
===========================
TensorRT LLM 为用户提供了一个易于使用的 Python API 来定义大语言模型 (LLMs),并支持最先进的优化技术,以便在 NVIDIA GPU 上高效执行推理。
[](https://nvidia.github.io/TensorRT-LLM/)
[](https://deepwiki.com/NVIDIA/TensorRT-LLM)
[](https://www.python.org/downloads/release/python-3123/)
[](https://www.python.org/downloads/release/python-31012/)
[](https://developer.nvidia.com/cuda-downloads)
[](https://pytorch.org)
[](https://github.com/NVIDIA/TensorRT-LLM/blob/main/tensorrt_llm/version.py)
[](https://github.com/NVIDIA/TensorRT-LLM/blob/main/LICENSE)
[架构](https://nvidia.github.io/TensorRT-LLM/developer-guide/overview.html) | [性能](https://nvidia.github.io/TensorRT-LLM/developer-guide/perf-overview.html) | [示例](https://nvidia.github.io/TensorRT-LLM/quick-start-guide.html) | [文档](https://nvidia.github.io/TensorRT-LLM/) | [路线图](https://github.com/NVIDIA/TensorRT-LLM/issues?q=is%3Aissue%20state%3Aopen%20label%3Aroadmap)
---
## 技术博客
* [02/06] 使用 Skip Softmax Attention 加速长上下文推理
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog16_Accelerating_Long_Context_Inference_with_Skip_Softmax_Attention.html)
* [01/09] 在 NVIDIA Blackwell GPU 上优化 DeepSeek-V3.2
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog15_Optimizing_DeepSeek_V32_on_NVIDIA_Blackwell_GPUs)
* [10/13] 在 TensorRT LLM 中扩展专家并行(第三部分:突破性能边界)
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog14_Scaling_Expert_Parallelism_in_TensorRT-LLM_part3.html)
* [09/26] TensorRT LLM 中的推理时计算实现
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog13_Inference_Time_Compute_Implementation_in_TensorRT-LLM.html)
* [09/19] 结合引导解码与推测解码:实现 CPU 与 GPU 无缝协作
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog12_Combining_Guided_Decoding_and_Speculative_Decoding.html)
* [08/29] ADP 平衡策略
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog10_ADP_Balance_Strategy.html)
* [08/05] 使用 TensorRT LLM 运行高性能 GPT-OSS-120B 推理服务器
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog9_Deploying_GPT_OSS_on_TRTLLM.html)
* [08/01] 在 TensorRT LLM 中扩展专家并行(第二部分:性能现状与优化)
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog8_Scaling_Expert_Parallelism_in_TensorRT-LLM_part2.html)
* [07/26] TensorRT LLM 中的 N-Gram 推测解码
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog7_NGram_performance_Analysis_And_Auto_Enablement.html)
* [06/19] TensorRT LLM 中的解耦式服务
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog5_Disaggregated_Serving_in_TensorRT-LLM.html)
* [06/05] 在 TensorRT LLM 中扩展专家并行(第一部分:大规模 EP 的设计与实现)
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog4_Scaling_Expert_Parallelism_in_TensorRT-LLM.html)
* [05/30] 在 NVIDIA Blackwell GPU 上优化 DeepSeek R1 吞吐量:开发者深度解析
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.html)
* [05/23] DeepSeek R1 MTP 实现与优化
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.html)
* [05/16] 突破延迟边界:在 NVIDIA B200 GPU 上优化 DeepSeek-R1 性能
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.html)
## 最新动态
* [08/05] 🌟 TensorRT LLM 为 OpenAI 最新的开源权重模型提供 Day-0 支持:GPT-OSS-120B [➡️ 链接](https://huggingface.co/openai/gpt-oss-120b) 和 GPT-OSS-20B [➡️ 链接](https://huggingface.co/openai/gpt-oss-20b)
* [07/15] 🌟 TensorRT LLM 为 LG AI Research 的最新模型 EXAONE 4.0 提供 Day-0 支持 [➡️ 链接](https://huggingface.co/LGAI-EXAONE/EXAONE-4.0-32B)
* [06/17] 加入 NVIDIA 和 DeepInfra,参加 6 月 26 日的开发者见面会 ✨ [➡️ 链接](https://events.nvidia.com/scaletheunscalablenextgenai)
* [05/22] Blackwell 与 Meta 的 Llama 4 Maverick 模型共同突破 1,000 TPS/用户 大关
✨ [➡️ 链接](https://developer.nvidia.com/blog/blackwell-breaks-the-1000-tps-user-barrier-with-metas-llama-4-maverick/)
* [04/10] TensorRT LLM DeepSeek R1 性能基准测试最佳实践现已发布。
✨ [➡️ 链接](https://nvidia.github.io/TensorRT-LLM/blogs/Best_perf_practice_on_DeepSeek-R1_in_TensorRT-LLM.html)
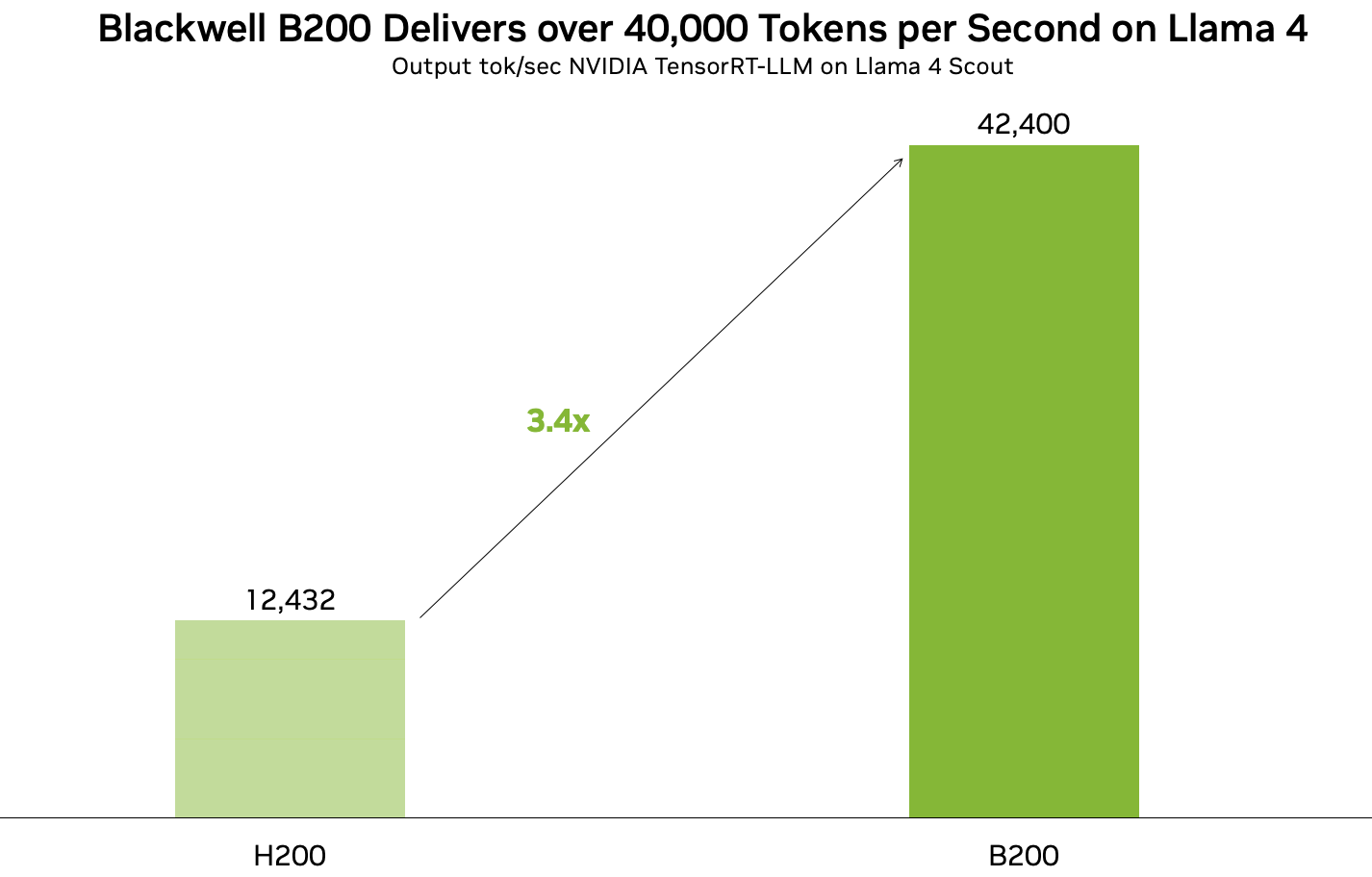
* [04/05] TensorRT LLM 可以在 B200 GPU 上以超过每秒 40,000 个令牌的速度运行 Llama 4!
* [03/22] TensorRT LLM 现已完全开源,开发工作已迁移至 GitHub!
* [03/18] 🚀🚀 NVIDIA Blackwell 借助 TensorRT LLM 提供世界纪录的 DeepSeek-R1 推理性能 [➡️ 链接](https://developer.nvidia.com/blog/nvidia-blackwell-delivers-world-record-deepseek-r1-inference-performance/)
* [02/28] 🌟 NAVER Place 利用 TensorRT LLM 优化基于 SLM 的垂直服务 [➡️ 链接](https://developer.nvidia.com/blog/spotlight-naver-place-optimizes-slm-based-vertical-services-with-nvidia-tensorrt-llm/)
* [02/25] 🌟 DeepSeek-R1 性能现已针对 Blackwell 优化 [➡️ 链接](https://huggingface.co/nvidia/DeepSeek-R1-FP4)
* [02/20] 探索完整指南,以最低成本为您的业务实现高精度、高吞吐量和低延迟 [此处](https://www.nvidia.com/en-us/solutions/ai/inference/balancing-cost-latency-and-performance-ebook/?ncid=so-twit-348956&linkId=100000341423615)。
* [02/18] 在 @AWS EKS 上通过自动扩缩解锁 #LLM 推理 ✨ [➡️ 链接](https://aws.amazon.com/blogs/hpc/scaling-your-llm-inference-workloads-multi-node-deployment-with-tensorrt-llm-and-triton-on-amazon-eks/)
* [02/12] 🦸⚡ 使用 DeepSeek-R1 和推理时扩缩实现 GPU 内核生成自动化
[➡️ 链接](https://developer.nvidia.com/blog/automating-gpu-kernel-generation-with-deepseek-r1-and-inference-time-scaling/?ncid=so-twit-997075&linkId=100000338909937)
* [02/12] 🌟 缩放定律如何驱动更智能、更强大的 AI
[➡️ 链接](https://blogs.nvidia.com/blog/ai-scaling-laws/?ncid=so-link-889273&linkId=100000338837832)
往期动态
* [2025/01/25] Nvidia 将 AI 重点转向推理成本与效率 [➡️ 链接](https://www.fierceelectronics.com/ai/nvidia-moves-ai-focus-inference-cost-efficiency?linkId=100000332985606)
* [2025/01/24] 🏎️ 使用 NVIDIA 全栈解决方案优化 AI 推理性能 [➡️ 链接](https://developer.nvidia.com/blog/optimize-ai-inference-performance-with-nvidia-full-stack-solutions/?ncid=so-twit-400810&linkId=100000332621049)
* [2025/01/23] 🚀 快速、低成本的推理是实现盈利 AI 的关键 [➡️ 链接](https://blogs.nvidia.com/blog/ai-inference-platform/?ncid=so-twit-693236-vt04&linkId=100000332307804)
* [2025/01/16] 介绍 TensorRT LLM 中新的 KV 缓存重用优化 [➡️ 链接](https://developer.nvidia.com/blog/introducing-new-kv-cache-reuse-optimizations-in-nvidia-tensorrt-llm/?ncid=so-twit-363876&linkId=100000330323229)
* [2025/01/14] 📣 Bing 向 LLM/SLM 模型转型:使用 TensorRT LLM 优化搜索 [➡️ 链接](https://blogs.bing.com/search-quality-insights/December-2024/Bing-s-Transition-to-LLM-SLM-Models-Optimizing-Search-with-TensorRT-LLM)
* [2025/01/04] ⚡使用 TensorRT LLM 推测解码将 Llama 3.3 70B 推理吞吐量提升 3 倍
[➡️ 链接](https://developer.nvidia.com/blog/boost-llama-3-3-70b-inference-throughput-3x-with-nvidia-tensorrt-llm-speculative-decoding/)
* [2024/12/10] ⚡ AI at Meta 的 Llama 3.3 70B 由 TensorRT-LLM 加速。 🌟 在推理、数学、指令遵循和工具使用方面与 Llama 3.1 405B 媲美的先进模型。探索预览版
[➡️ 链接](https://build.nvidia.com/meta/llama-3_3-70b-instruct)
* [2024/12/03] 🌟 将您的 AI 推理吞吐量提升高达 3.6 倍。我们现在支持推测解码,并通过 NVIDIA TensorRT-LLM 实现三倍令牌吞吐量。非常适合您的生成式 AI 应用。 ⚡在这篇技术深度解析中了解详情
[➡️ 链接](https://nvda.ws/3ZCZTzD)
* [2024/12/02] 正在为性能关键型应用部署 ONNX 模型?试试我们的 NVIDIA Nsight Deep Learning Designer ⚡ 一个用户友好的 GUI,并与 NVIDIA TensorRT 紧密集成,提供:
✅ ONNX 模型图的直观可视化
✅ 快速调整模型架构和参数
✅ 使用 ORT 或 TensorRT 进行详细的性能分析
✅ 轻松构建 TensorRT 引擎
[➡️ 链接](https://developer.nvidia.com/nsight-dl-designer?ncid=so-link-485689&linkId=100000315016072)
* [2024/11/26] 📣 推出适用于 Jetson AGX Orin 的 TensorRT LLM,通过 TensorRT LLM 代码库的 v0.12.0-jetson 分支在 JetPack 6.1 中提供初始支持,使在 Jetson AGX Orin 上的部署更加容易。 ✅ 预编译的 TensorRT LLM wheels 和容器,便于集成 ✅ 全面的指南和文档助您入门
[➡️ 链接](https://forums.developer.nvidia.com/t/tensorrt-llm-for-jetson/313227?linkId=100000312718869)
* [2024/11/21] NVIDIA TensorRT LLM 多块注意力在 NVIDIA HGX H200 上为长序列长度提升超过 3 倍的吞吐量
[➡️ 链接](https://developer.nvidia.com/blog/nvidia-tensorrt-llm-multiblock-attention-boosts-throughput-by-more-than-3x-for-long-sequence-lengths-on-nvidia-hgx-h200/)
* [2024/11/19] Llama 3.2 全栈优化在 NVIDIA GPU 上解锁高性能
[➡️ 链接](https://developer.nvidia.com/blog/llama-3-2-full-stack-optimizations-unlock-high-performance-on-nvidia-gpus/?ncid=so-link-721194)
* [2024/11/09] 🚀🚀🚀 借助 NVSwitch 和 TensorRT LLM MultiShot 实现 3 倍更快的 AllReduce
[➡️ 链接](https://developer.nvidia.com/blog/3x-faster-allreduce-with-nvswitch-and-tensorrt-llm-multishot/)
* [2024/11/09] ✨ NVIDIA 与 LG AI Research 的 AI 模型共同推进 AI 生态系统 🙌
[➡️ 链接](https://blogs.nvidia.co.kr/blog/nvidia-lg-ai-research/)
* [2024/11/02] 🌟🌟🌟 NVIDIA 和 LlamaIndex 开发者竞赛
🙌 参与即有机会赢取包括 NVIDIA® GeForce RTX™ 4080 SUPER GPU、DLI 积分等在内的奖品 🙌
[➡️ 链接](https://developer.nvidia.com/llamaindex-developer-contest)
* [2024/10/28] 🏎️🏎️🏎️ NVIDIA GH200 超级芯片在多轮 Llama 模型交互中将推理速度提升 2 倍
[➡️ 链接](https://developer.nvidia.com/blog/nvidia-gh200-superchip-accelerates-inference-by-2x-in-multiturn-interactions-with-llama-models/)
* [2024/10/22] 新的 📝 分步指南,介绍如何:
✅ 使用 NVIDIA TensorRT-LLM 优化 LLMs,
✅ 使用 Triton Inference Server 部署优化后的模型,
✅ 在 Kubernetes 环境中自动扩缩 LLMs 部署。
🙌 技术深度解析:
[➡️ 链接](https://nvda.ws/3YgI8UT)
* [2024/10/07] 🚀🚀🚀使用 NVIDIA 加速库优化 Microsoft Bing 视觉搜索
[➡️ 链接](https://developer.nvidia.com/blog/optimizing-microsoft-bing-visual-search-with-nvidia-accelerated-libraries/)
* [2024/09/29] 🌟 AI at Meta PyTorch + TensorRT v2.4 🌟 ⚡TensorRT 10.1 ⚡PyTorch 2.4 ⚡CUDA 12.4 ⚡Python 3.12
[➡️ 链接](https://github.com/pytorch/TensorRT/releases/tag/v2.4.0)
* [2024/09/17] ✨ NVIDIA TensorRT LLM 见面会
[➡️ 链接](https://drive.google.com/file/d/1RR8GqC-QbuaKuHj82rZcXb3MS20SWo6F/view?usp=share_link)
* [2024/09/17] ✨ 在 Databricks 使用 TensorRT-LLM 加速