OA0 ›
代码 ›
Seldon Core — 机器学习部署系统
Seldon Core — 机器学习部署系统
chance · 2025-10-23 14:51:33 · 75 次点击 · 0 条评论Seldon Core:极速、生产就绪的机器学习平台
在 Kubernetes 上大规模部署机器学习模型的平台。
Seldon Core V2 现已发布

Seldon Core V2 现已发布。如果你是 Seldon Core 的新用户,我们建议你从这里开始。查看此处的文档,并务必在我们的 Slack 社区留下反馈,或在仓库中提交错误或功能请求。代码库可在此分支中找到。
继续阅读以获取 Seldon Core V1 的信息...
![]()
概述
Seldon Core 将你的 ML 模型(Tensorflow、Pytorch、H2o 等)或语言封装器(Python、Java 等)转换为生产级的 REST/GRPC 微服务。
Seldon 可处理数千个生产机器学习模型的扩展,并提供开箱即用的高级机器学习功能,包括高级指标、请求日志记录、解释器、异常检测器、A/B 测试、金丝雀发布等。
- 阅读 Seldon Core 文档
- 加入我们的社区 Slack 提问
- 从 Seldon Core 笔记本示例 开始
- 参加我们每两周一次的在线工作组会议 : Google 日历
- 了解如何开始贡献
- 查看深入探讨 Seldon Core 组件的博客
- 观看一些使用 Seldon Core 的视频和演讲
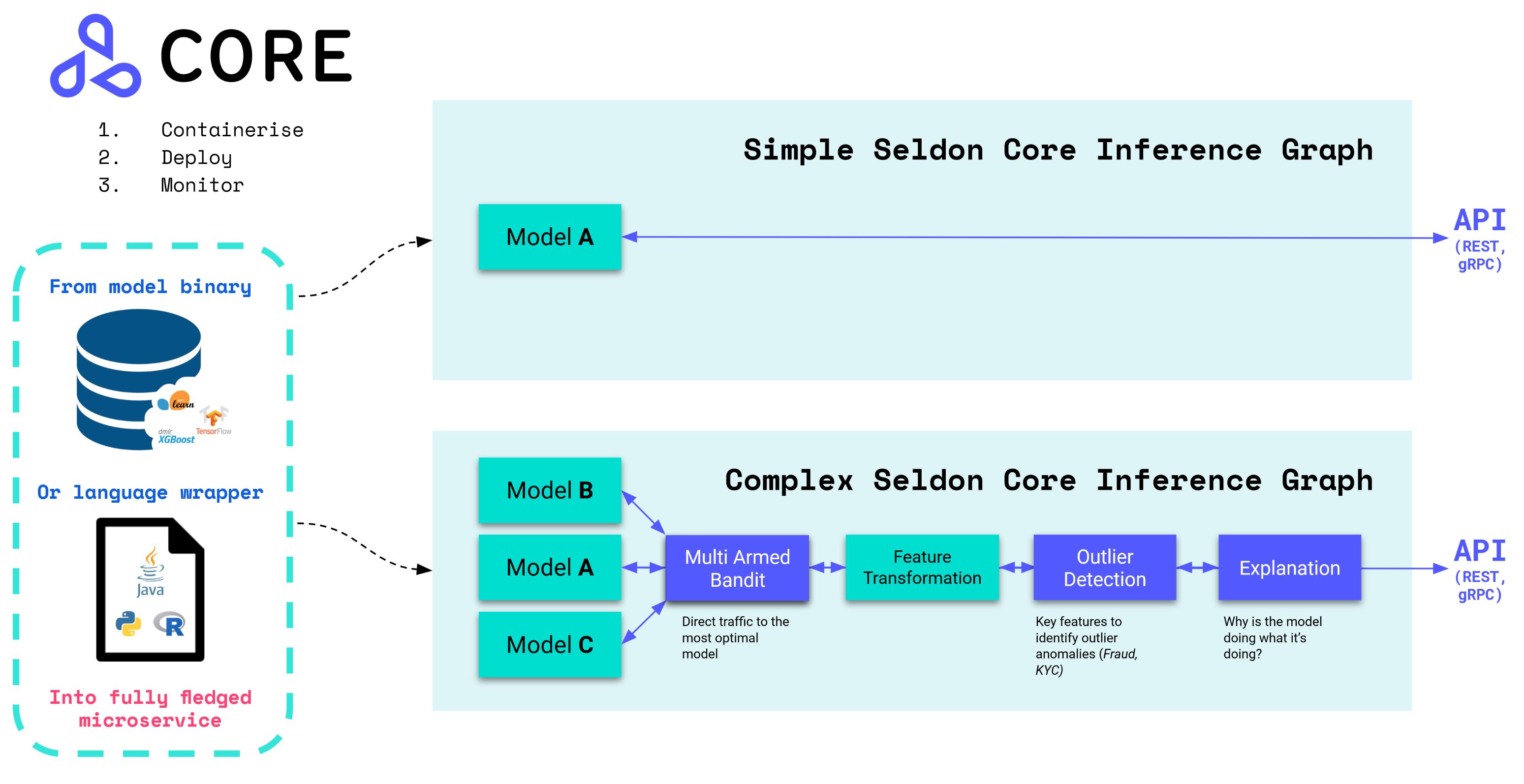
高级特性
Seldon Core 拥有超过 200 万次安装,被各组织用于管理大规模机器学习模型部署,其主要优势包括:
- 使用我们的预打包推理服务器、自定义服务器 或语言封装器 轻松容器化 ML 模型。
- 开箱即用的端点,可通过 Swagger UI、Seldon Python 客户端或 Curl / GRPCurl 进行测试。
- 云无关,已在 AWS EKS、Azure AKS、Google GKE、阿里云、Digital Ocean 和 Openshift 上测试。
- 由预测器、转换器、路由器、组合器等 构成的强大而丰富的推理图。
- 元数据溯源,确保每个模型都能追溯到其相应的训练系统、数据和指标。
- 高级且可定制的指标,集成 Prometheus 和 Grafana。
- 通过模型输入输出请求与 Elasticsearch 的日志集成 实现完全可审计性。
- 通过与 Jaeger 的集成 实现微服务分布式追踪,洞察跨微服务跳转的延迟。
- 通过一致的安全与更新策略 维护安全、可靠和稳健的系统。
快速开始
通过我们的预打包推理服务器和语言封装器,使用 Seldon Core 部署模型变得非常简单。下面你可以看到如何部署我们的“hello world Iris”示例。你可以在我们的文档快速入门 中查看更多关于这些工作流的详细信息。
安装 Seldon Core
使用 Helm 3 快速安装(你也可以使用 Kustomize):
kubectl create namespace seldon-system
helm install seldon-core seldon-core-operator \
--repo https://storage.googleapis.com/seldon-charts \
--set usageMetrics.enabled=true \
--namespace seldon-system \
--set istio.enabled=true
# 你可以使用 --set ambassador.enabled=true 来设置 ambassador
使用预打包模型服务器部署模型
我们为一些最流行的深度学习和机器学习框架提供了优化的模型服务器,允许你部署训练好的模型二进制文件/权重,而无需容器化或修改它们。
你只需将模型二进制文件上传到你偏好的对象存储中,本例中我们有一个训练好的 scikit-learn iris 模型存储在 Google 存储桶中:
gs://seldon-models/v1.20.0-dev/sklearn/iris/model.joblib
创建一个命名空间来运行你的模型:
kubectl create namespace seldon
然后,我们可以使用 scikit-learn 的预打包模型服务器(SKLEARN_SERVER),通过运行下面的 kubectl apply 命令,将此模型部署到我们的 Kubernetes 集群:
$ kubectl apply -f - << END
apiVersion: machinelearning.seldon.io/v1
kind: SeldonDeployment
metadata:
name: iris-model
namespace: seldon
spec:
name: iris
predictors:
- graph:
implementation: SKLEARN_SERVER
modelUri: gs://seldon-models/v1.20.0-dev/sklearn/iris
name: classifier
name: default
replicas: 1
END
向已部署的模型发送 API 请求
每个部署的模型都通过我们的 OpenAPI 模式公开了一个标准化的用户界面来发送请求。
可以通过端点 http://<ingress_url>/seldon/<namespace>/<model-name>/api/v1.0/doc/ 访问,该端点允许你直接通过浏览器发送请求。
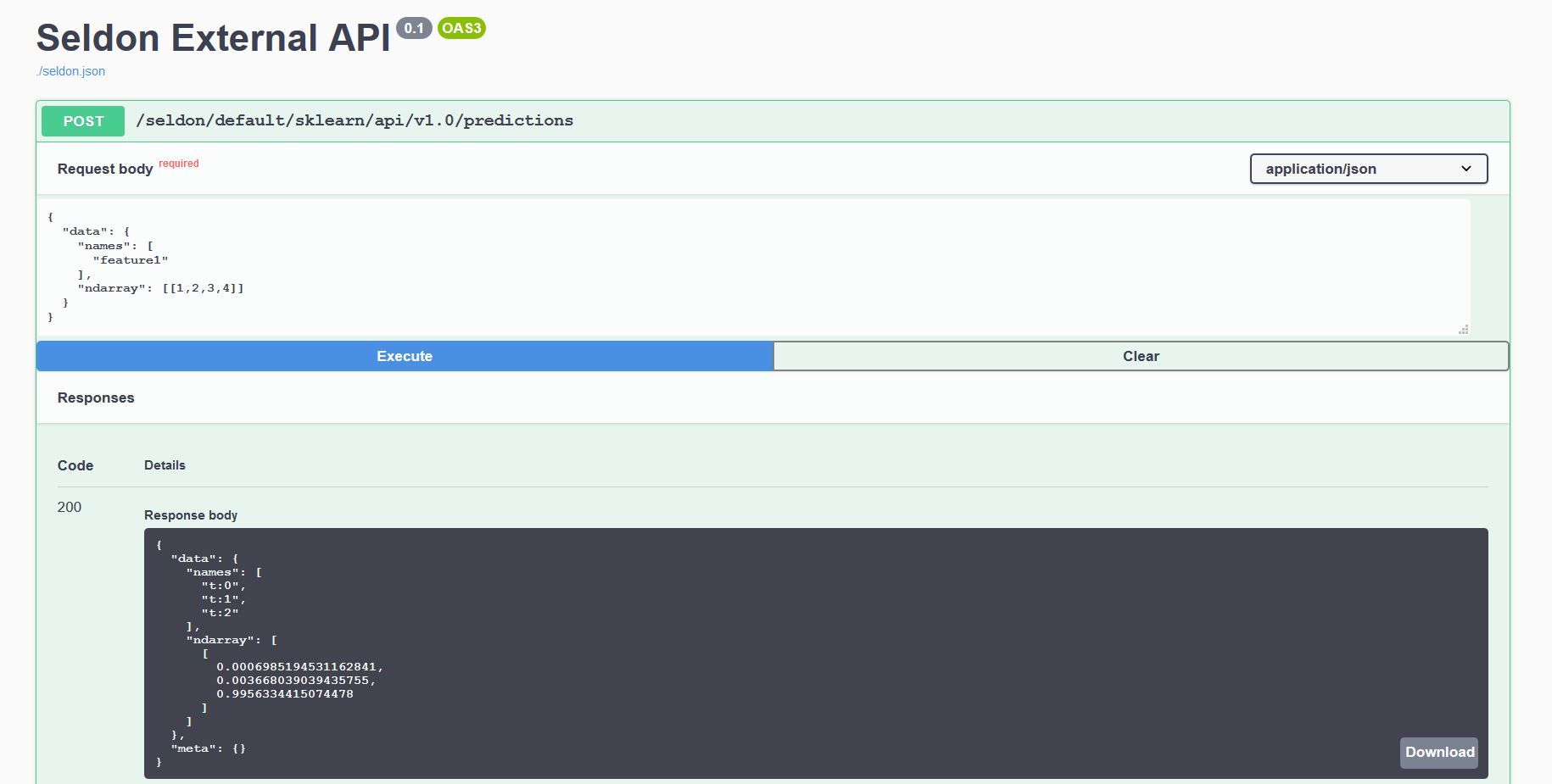
或者,你也可以使用我们的 Seldon Python 客户端 或另一个 Linux CLI 以编程方式发送请求:
$ curl -X POST http://<ingress>/seldon/seldon/iris-model/api/v1.0/predictions \
-H 'Content-Type: application/json' \
-d '{ "data": { "ndarray": [[1,2,3,4]] } }'
{
"meta" : {},
"data" : {
"names" : [
"t:0",
"t:1",
"t:2"
],
"ndarray" : [
[
0.000698519453116284,
0.00366803903943576,
0.995633441507448
]
]
}
}
使用语言封装器部署自定义模型
对于具有自定义依赖项(例如第三方库、操作系统二进制文件甚至外部系统)的更自定义的深度学习和机器学习用例,我们可以使用任何 Seldon Core 语言封装器。
你只需编写一个封装类来公开模型的逻辑;例如,在 Python 中,我们可以创建一个文件 Model.py:
import pickle
class Model:
def __init__(self):
self._model = pickle.loads( open("model.pickle", "rb") )
def predict(self, X):
output = self._model(X)
return output
现在,我们可以使用 Seldon Core s2i 工具 将我们的类文件容器化,生成 sklearn_iris 镜像:
s2i build . seldonio/seldon-core-s2i-python3:0.18 sklearn_iris:0.1
然后我们将其部署到 Seldon Core Kubernetes 集群:
$ kubectl apply -f - << END
apiVersion: machinelearning.seldon.io/v1
kind: SeldonDeployment
metadata:
name: iris-model
namespace: model-namespace
spec:
name: iris
predictors:
- componentSpecs:
- spec:
containers:
- name: classifier
image: sklearn_iris:0.1
graph:
name: classifier
name: default
replicas: 1
END
向已部署的模型发送 API 请求
每个部署的模型都通过我们的 OpenAPI 模式公开了一个标准化的用户界面来发送请求。
可以通过端点 http://<ingress_url>/seldon/<namespace>/<model-name>/api/v1.0/doc/ 访问,该端点允许你直接通过浏览器发送请求。
或者,你也可以使用我们的 Seldon Python 客户端 或另一个 Linux CLI 以编程方式发送请求:
$ curl -X POST http://<ingress>/seldon/model-namespace/iris-model/api/v1.0/predictions \
-H 'Content-Type: application/json' \
-d '{ "data": { "ndarray": [1,2,3,4] } }' | json_pp
{
"meta" : {},
"data" : {
"names" : [
"t:0",
"t:1",
"t:2"
],
"ndarray" : [
[
0.000698519453116284,
0.00366803903943576,
0.995633441507448
]
]
}
}
深入了解高级生产 ML 集成
任何使用 Seldon Core 部署和编排的模型都提供开箱即用的机器学习洞察,用于监控、管理、扩展和调试。
以下是一些核心组件,以及提供如何设置它们的进一步见解的链接。
|
使用 Prometheus 的标准和自定义指标 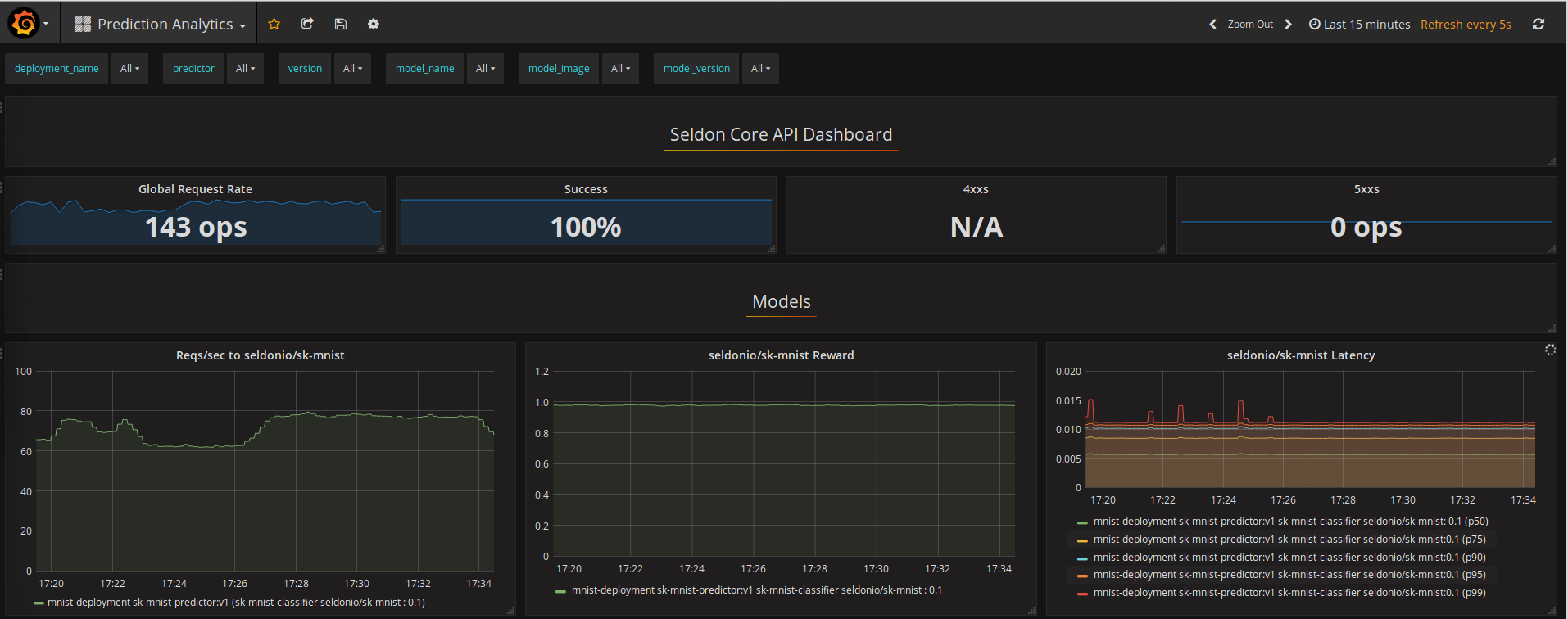
|
使用 ELK 请求日志记录实现完整审计跟踪 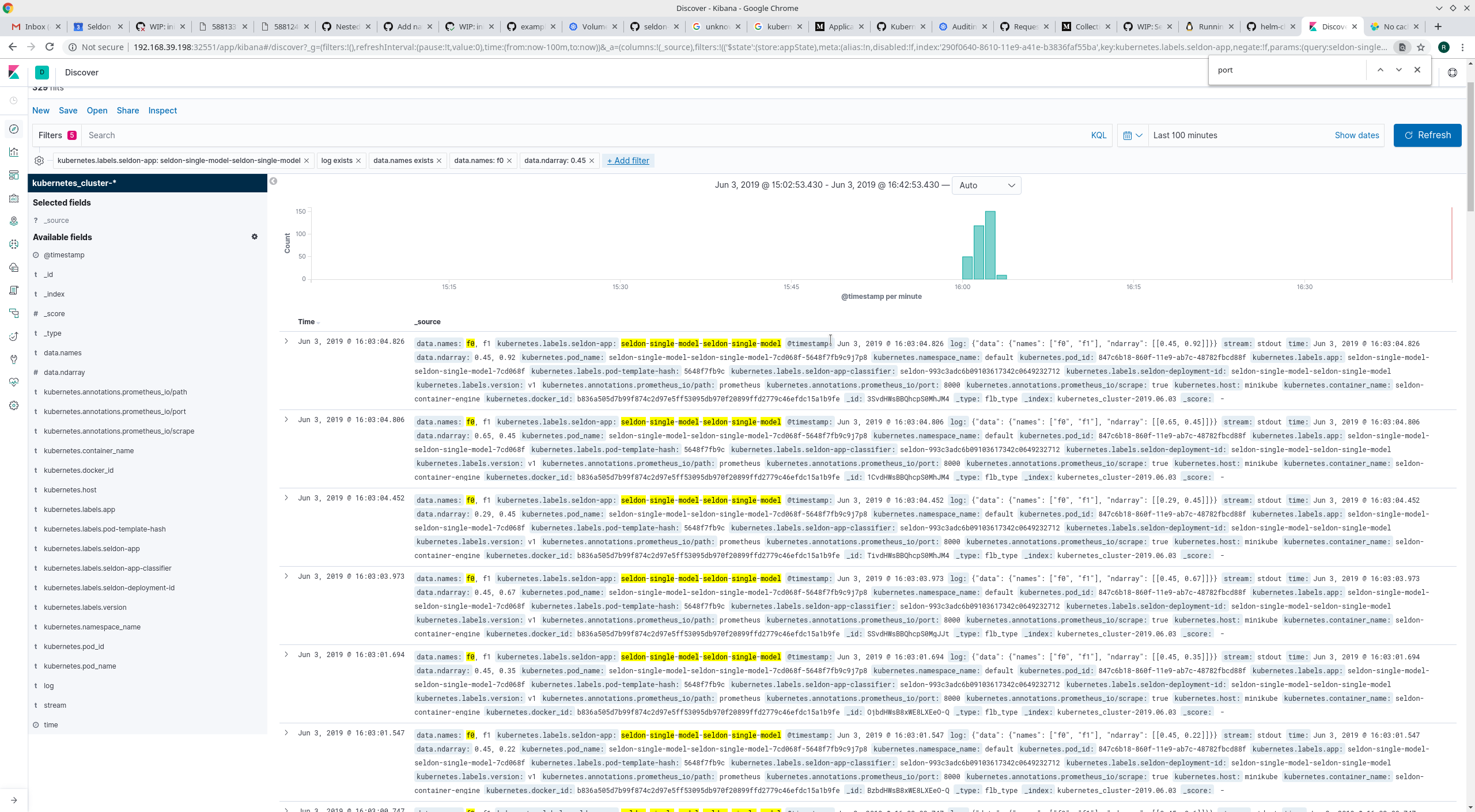
|
|
用于机器学习可解释性的解释器 
|
用于监控的异常和对抗性检测器 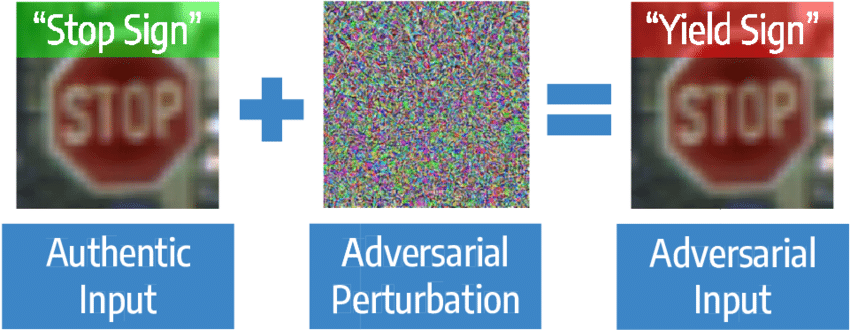
|
|
大规模 MLOps 的 CI/CD 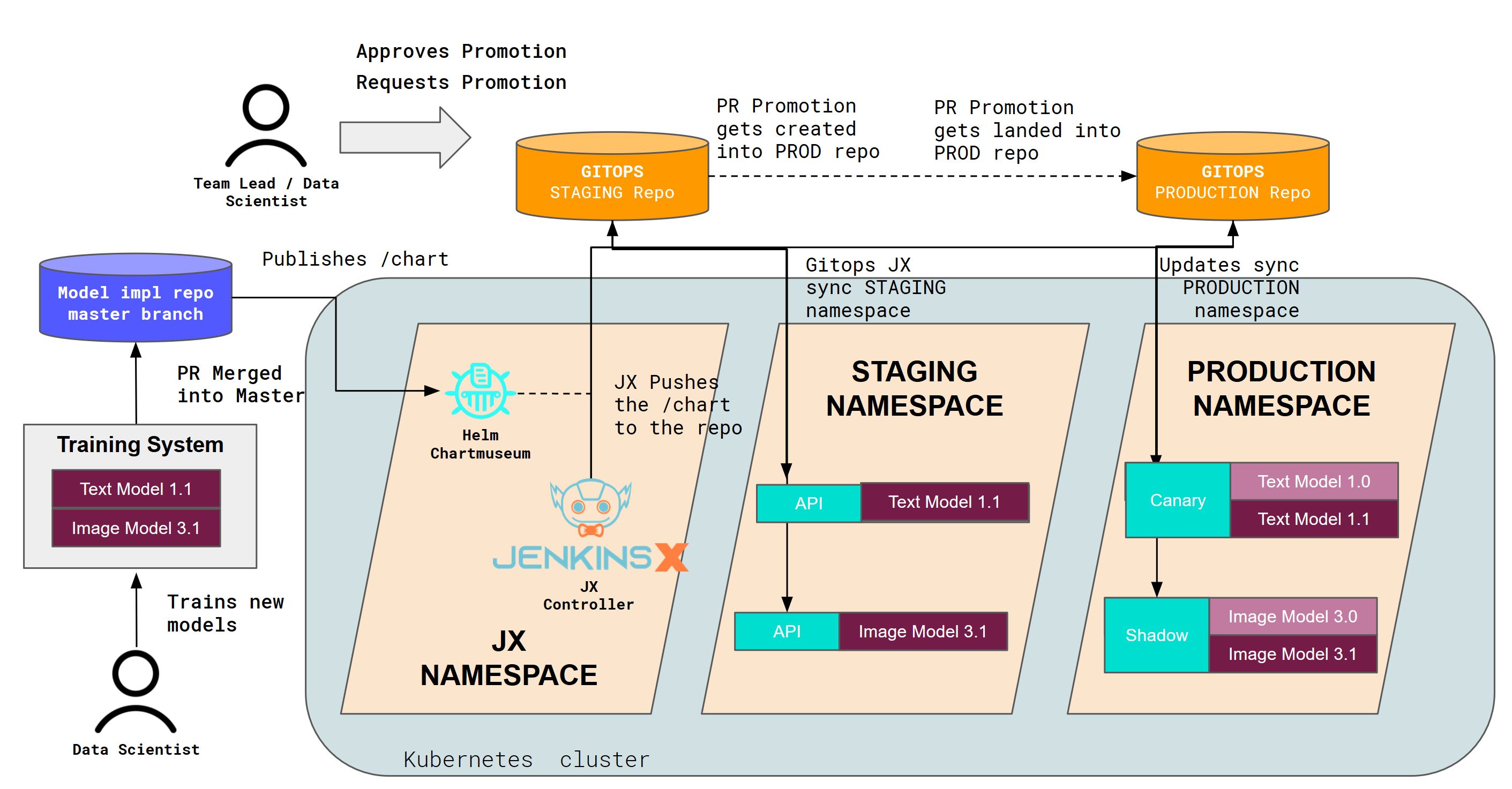
|
用于性能监控的分布式追踪 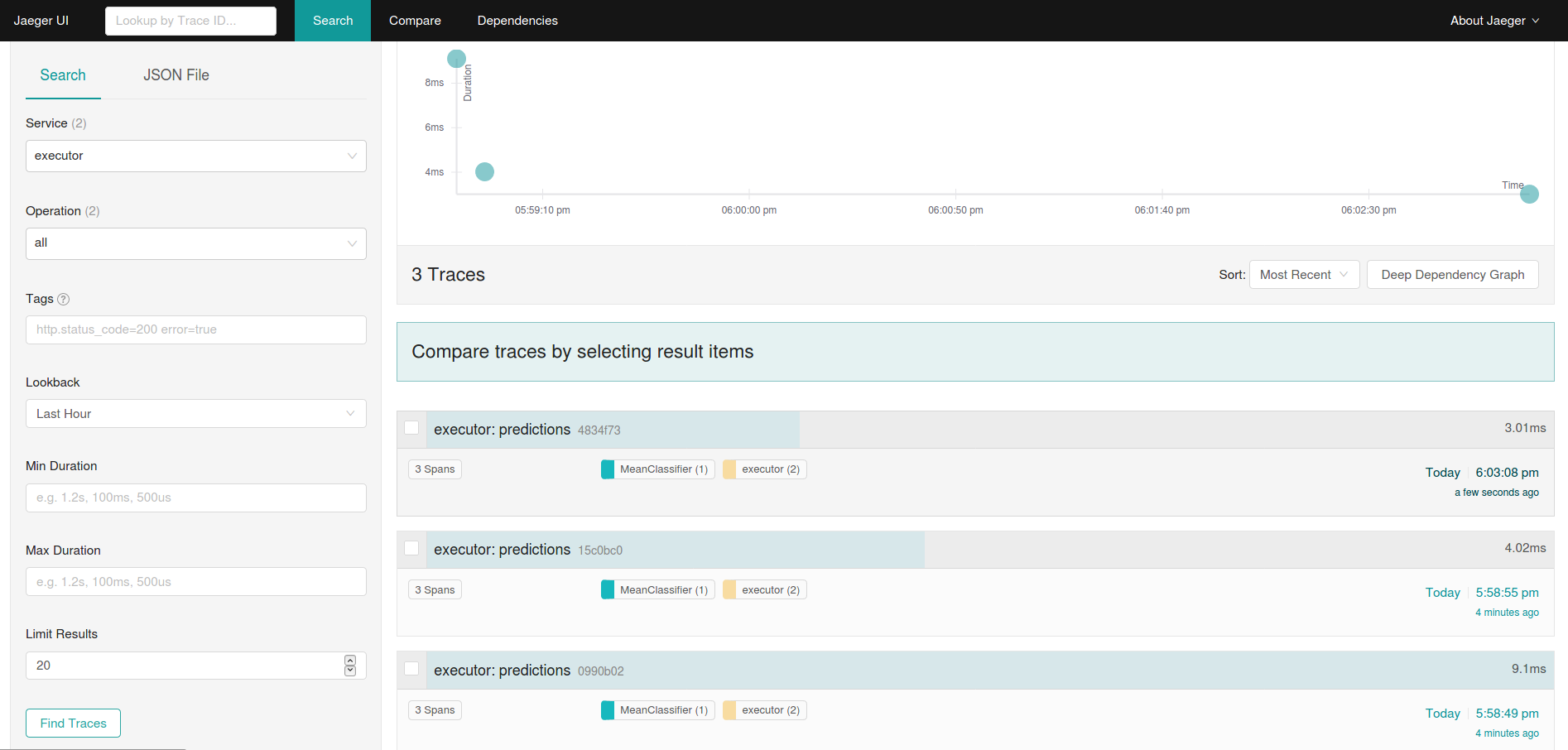
|