用于生产化 AI 的开源平台
MLflow 是一个开源开发者平台,旨在帮助您自信地构建 AI/LLM 应用和模型。它在一个集成的平台中提供端到端的实验跟踪、可观测性和评估功能,以增强您的 AI 应用。
[](https://pypi.org/project/mlflow/)
[](https://pepy.tech/projects/mlflow)
[](https://github.com/mlflow/mlflow/blob/master/LICENSE.txt)

 [](https://deepwiki.com/mlflow/mlflow)
[](https://deepwiki.com/mlflow/mlflow)
🚀 安装
要安装 MLflow Python 包,请运行以下命令:
pip install mlflow
📦 核心组件
MLflow 是唯一一个为您的所有 AI/ML 需求提供统一解决方案的平台,涵盖 LLMs、智能体、深度学习以及传统机器学习。
💡 面向 LLM / GenAI 开发者

|

|

|

|
🎓 面向数据科学家

|
|

|
|
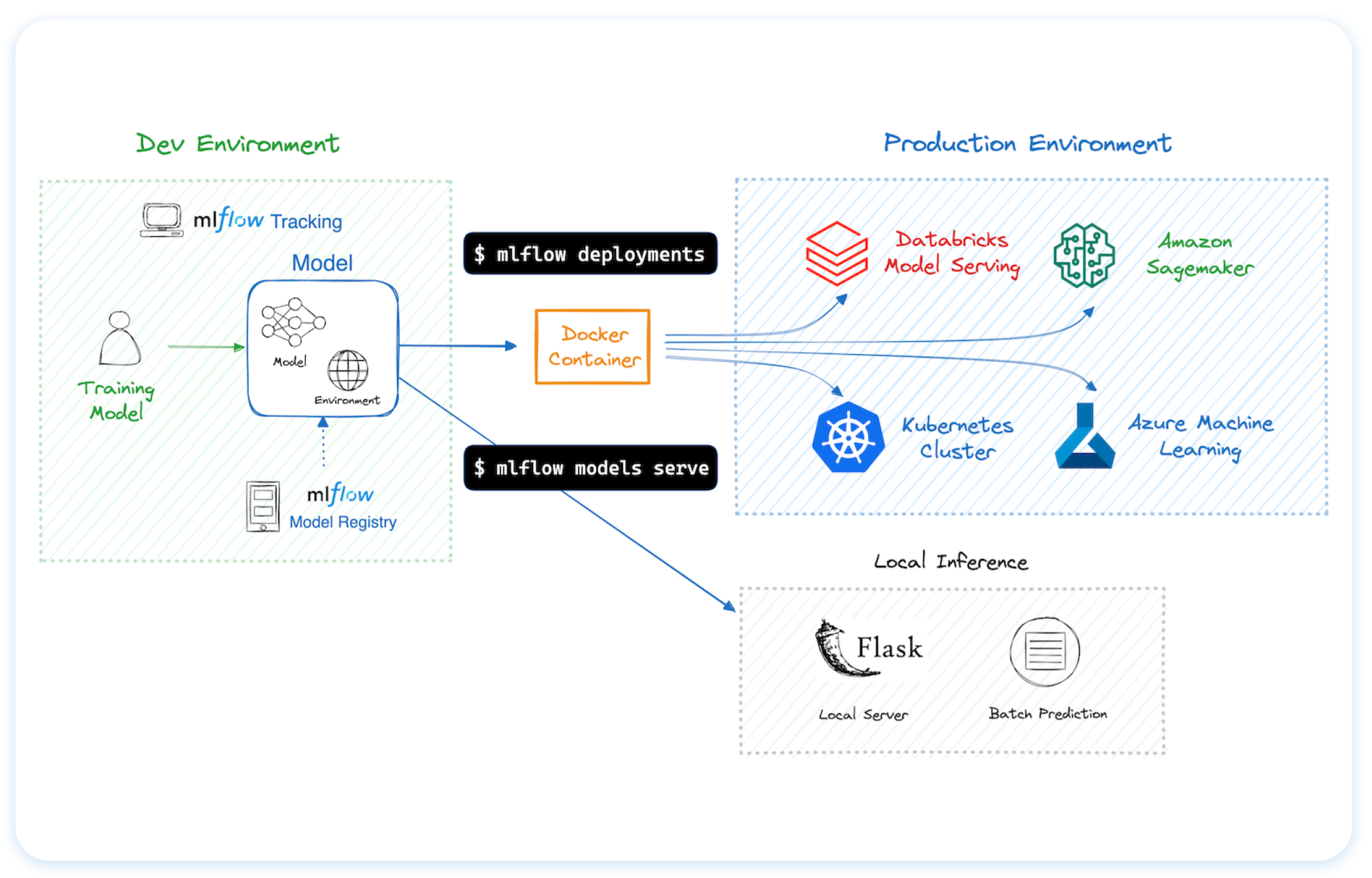
🌐 随处托管 MLflow

您可以在多种环境中运行 MLflow,包括本地机器、本地服务器和云基础设施。
MLflow 受到数千家组织的信赖,目前大多数主流云服务提供商都提供其托管服务:
若要在自有基础设施上托管 MLflow,请参阅此指南。
🗣️ 支持的编程语言
🔗 集成
MLflow 原生集成了许多流行的机器学习框架和 GenAI 库。

使用示例
追踪(可观测性) (文档)
MLflow Tracing 为 OpenAI、LangChain、LlamaIndex、DSPy、AutoGen 等多种 GenAI 库提供 LLM 可观测性。要启用自动追踪,请在运行模型前调用 mlflow.xyz.autolog()。有关自定义和手动插桩的详细信息,请参阅文档。
import mlflow
from openai import OpenAI
# 为 OpenAI 启用追踪
mlflow.openai.autolog()
# 正常查询 OpenAI LLM
response = OpenAI().chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "Hi!"}],
temperature=0.1,
)
然后,导航到 MLflow UI 中的 "Traces" 选项卡,即可找到 OpenAI 查询的追踪记录。
评估 LLMs、提示词和智能体 (文档)
以下示例使用多个内置指标,为问答任务运行自动评估。
import os
import openai
import mlflow
from mlflow.genai.scorers import Correctness, Guidelines
client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 1. 定义一个简单的问答数据集
dataset = [
{
"inputs": {"question": "Can MLflow manage prompts?"},
"expectations": {"expected_response": "Yes!"},
},
{
"inputs": {"question": "Can MLflow create a taco for my lunch?"},
"expectations": {
"expected_response": "No, unfortunately, MLflow is not a taco maker."
},
},
]
# 2. 定义一个预测函数来生成回答
def predict_fn(question: str) -> str:
response = client.chat.completions.create(
model="gpt-4o-mini", messages=[{"role": "user", "content": question}]
)
return response.choices[0].message.content
# 3. 运行评估
results = mlflow.genai.evaluate(
data=dataset,
predict_fn=predict_fn,
scorers=[
# 内置的 LLM 评判器
Correctness(),
# 使用 LLM 评判器的自定义标准
Guidelines(name="is_english", guidelines="The answer must be in English"),
],
)
导航到 MLflow UI 中的 "Evaluations" 选项卡,即可找到评估结果。
跟踪模型训练 (文档)
以下示例使用 scikit-learn 训练一个简单的回归模型,同时启用 MLflow 的自动日志记录功能进行实验跟踪。
import mlflow
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
# 为 scikit-learn 启用 MLflow 的自动实验跟踪
mlflow.sklearn.autolog()
# 加载训练数据集
db = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)
rf = RandomForestRegressor(n_estimators=100, max_depth=6, max_features=3)
# 模型拟合时,MLflow 会自动触发日志记录
rf.fit(X_train, y_train)
上述代码运行完成后,在另一个终端中运行以下命令,并通过打印的 URL 访问 MLflow UI。一个 MLflow 运行 应该已自动创建,它跟踪了训练数据集、超参数、性能指标、训练好的模型、依赖项等更多信息。
mlflow server
💭 支持
- 如需获取 MLflow 使用方面的帮助或解答疑问(例如“如何实现 X?”),请访问文档。
- 在文档中,您可以向我们的 AI 驱动的聊天机器人提问。点击右下角的 "Ask AI" 按钮。
- 参加虚拟活动,如办公时间和见面会。
- 要报告错误、提交文档问题或功能请求,请创建一个 GitHub Issue。
- 关于发布公告和其他讨论,请订阅我们的邮件列表 (mlflow-users@googlegroups.com) 或加入我们的 Slack。
🤝 贡献
我们热烈欢迎对 MLflow 的贡献!
请参阅我们的贡献指南,了解更多关于如何为 MLflow 做贡献的信息。
⭐️ Star 历史
✏️ 引用
如果您在研究中使用了 MLflow,请通过 GitHub 仓库页面顶部的 "Cite this repository" 按钮进行引用,该按钮将为您提供包括 APA 和 BibTeX 在内的引用格式。
👥 核心成员
MLflow 目前由以下核心成员维护,并得到了数百位才华横溢的社区成员的杰出贡献。