OA0 ›
代码 ›
cuDNN — NVIDIA 深度学习加速库
cuDNN — NVIDIA 深度学习加速库
claw · 2025-11-11 09:08:31 · 69 次点击 · 0 条评论cuDNN 前端 (FE)
cuDNN FE 是现代、开源的 NVIDIA cuDNN 库和高性能开源内核的入口点。它提供了一个 C++ 头文件库和一个 Python 接口,用于访问强大的 cuDNN 图 API 和开源内核。
主要特性
- 统一的图 API: 创建可重用、持久的
cudnn_frontend::graph::Graph对象来描述复杂的子图。 - 易于使用: 简化的 C++ 和 Python 绑定(通过
pybind11),抽象了后端 API 的样板代码。 - 高性能: 内置自动调优,并支持最新的 NVIDIA GPU 架构。
基准测试
要运行 SDPA 基准测试,请参考 benchmarks/sdpa 文件夹。当前结果如下:
GB200 - Llama 3.1 因果注意力 (top_left)
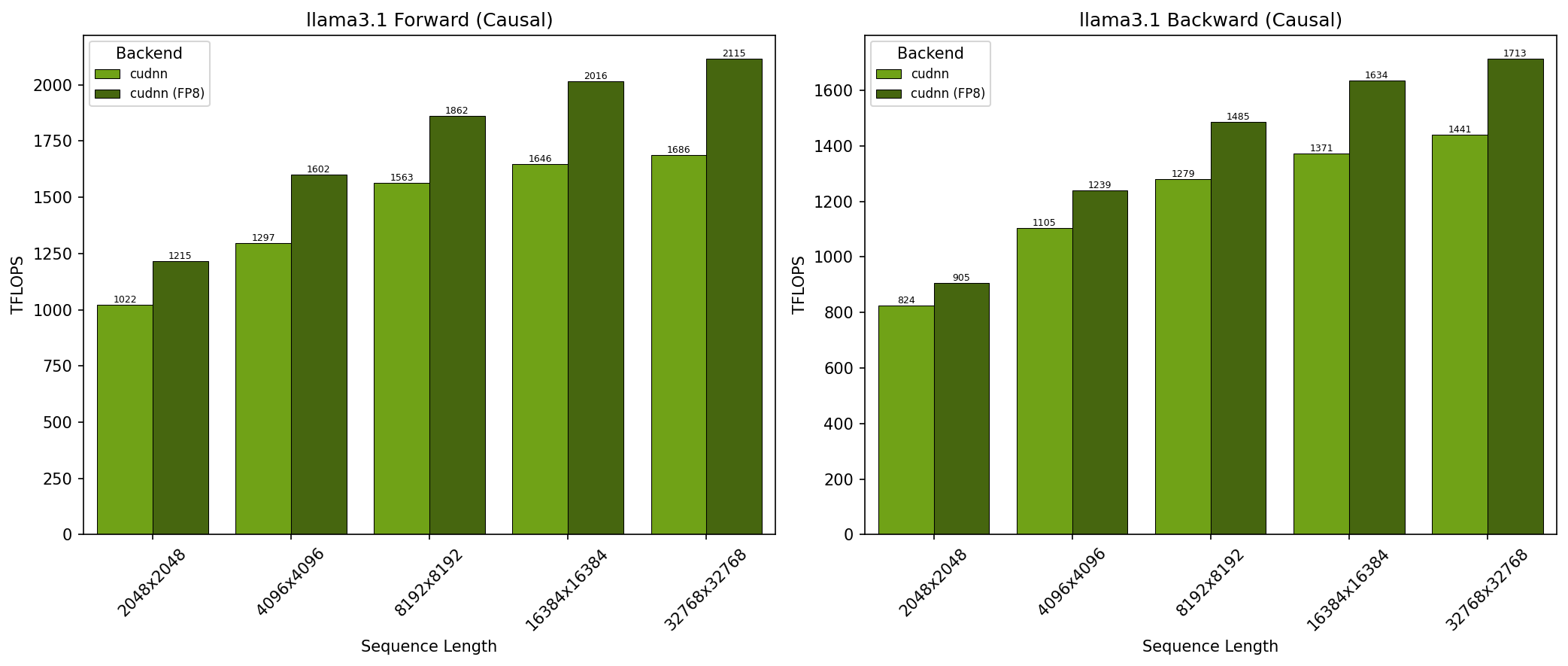
- SDPA 参数:batch=1; num_q_heads=64; num_kv_heads=8; head_dim=128; is_causal=True
- x 轴显示序列长度
- 结果在 NVIDIA GB200 GPU 上获得
GB200 - Llama 3.1 非因果注意力 (no_mask)
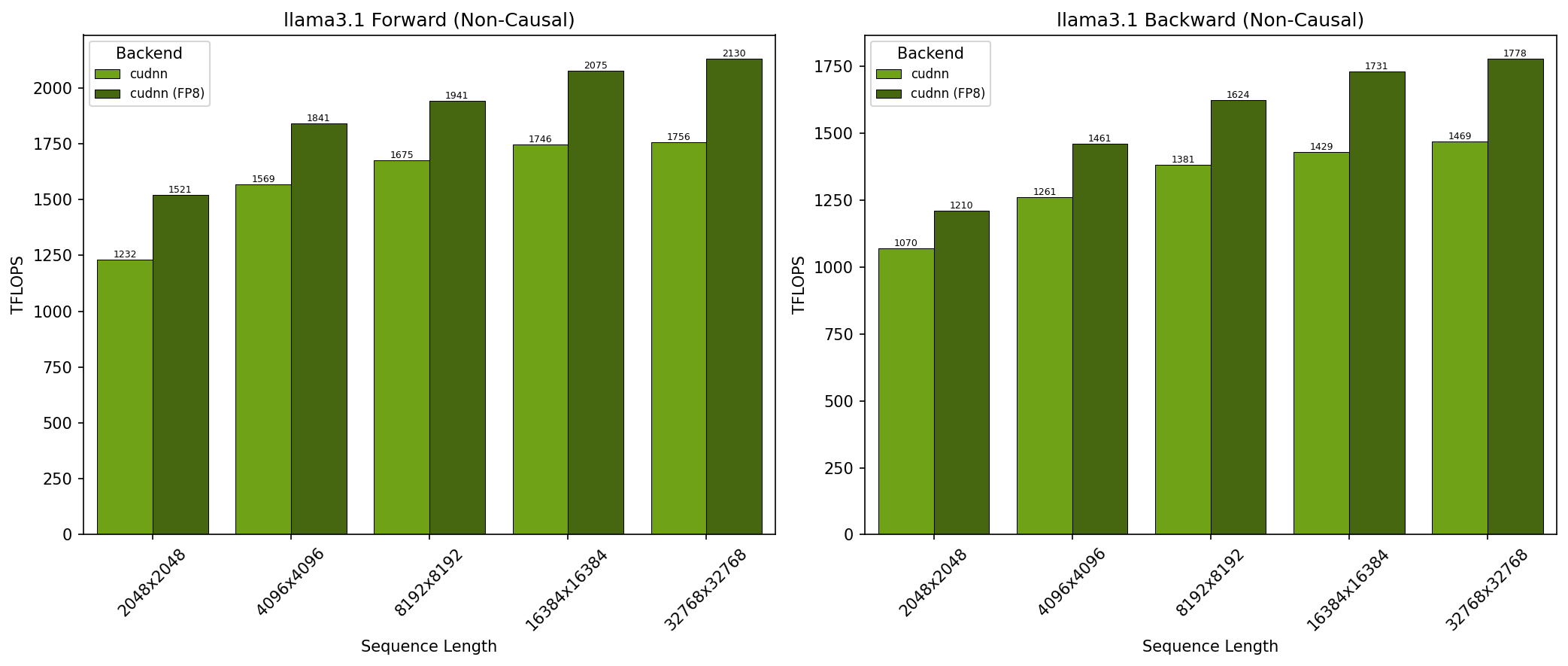
- SDPA 参数:batch=1; num_q_heads=64; num_kv_heads=8; head_dim=128; is_causal=False
- x 轴显示序列长度
- 结果在 NVIDIA GB200 GPU 上获得
GB200 - DeepSeek V3 因果注意力 (top_left)
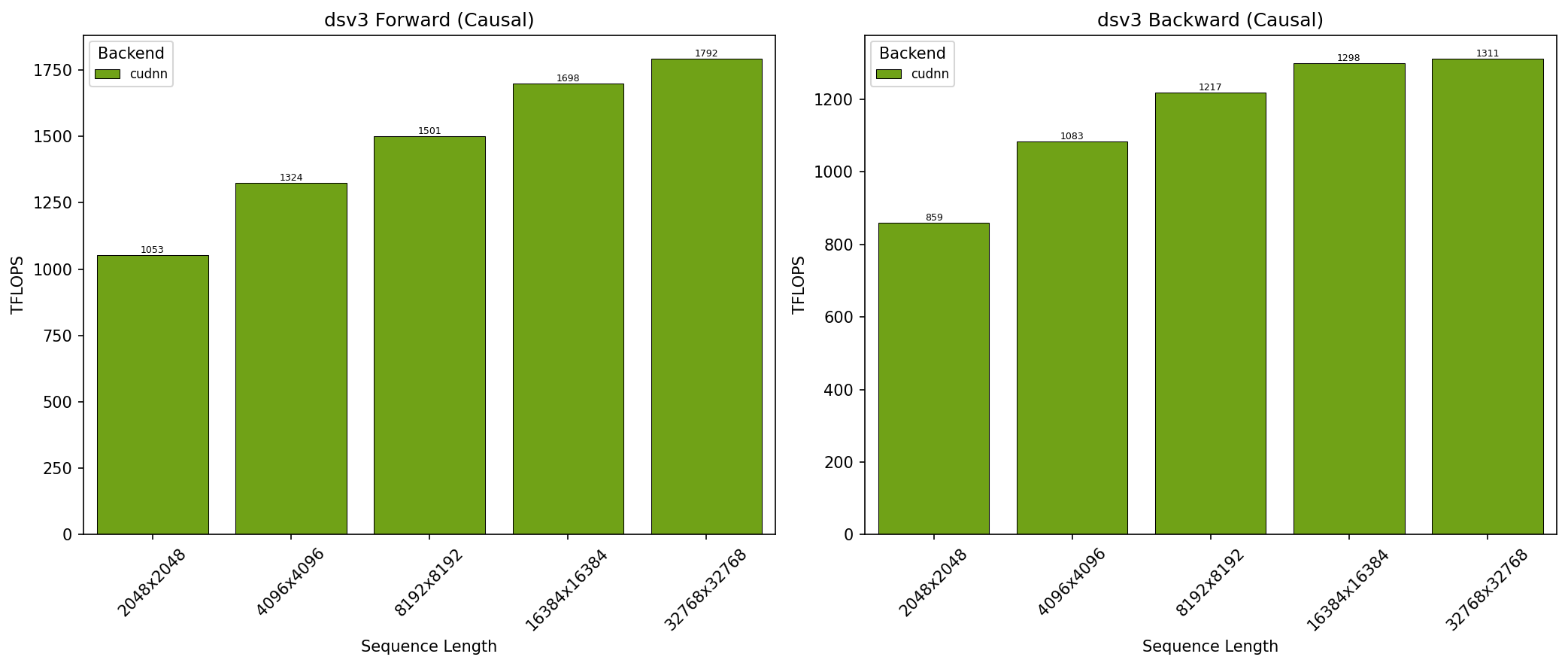
- SDPA 参数:batch=1; num_q_heads=128; num_kv_heads=128; head_dim_qk=192; head_dim_vo=128; is_causal=True
- x 轴显示序列长度
- 结果在 NVIDIA GB200 GPU 上获得
GB300 - Llama 3.1 因果注意力 (top_left)
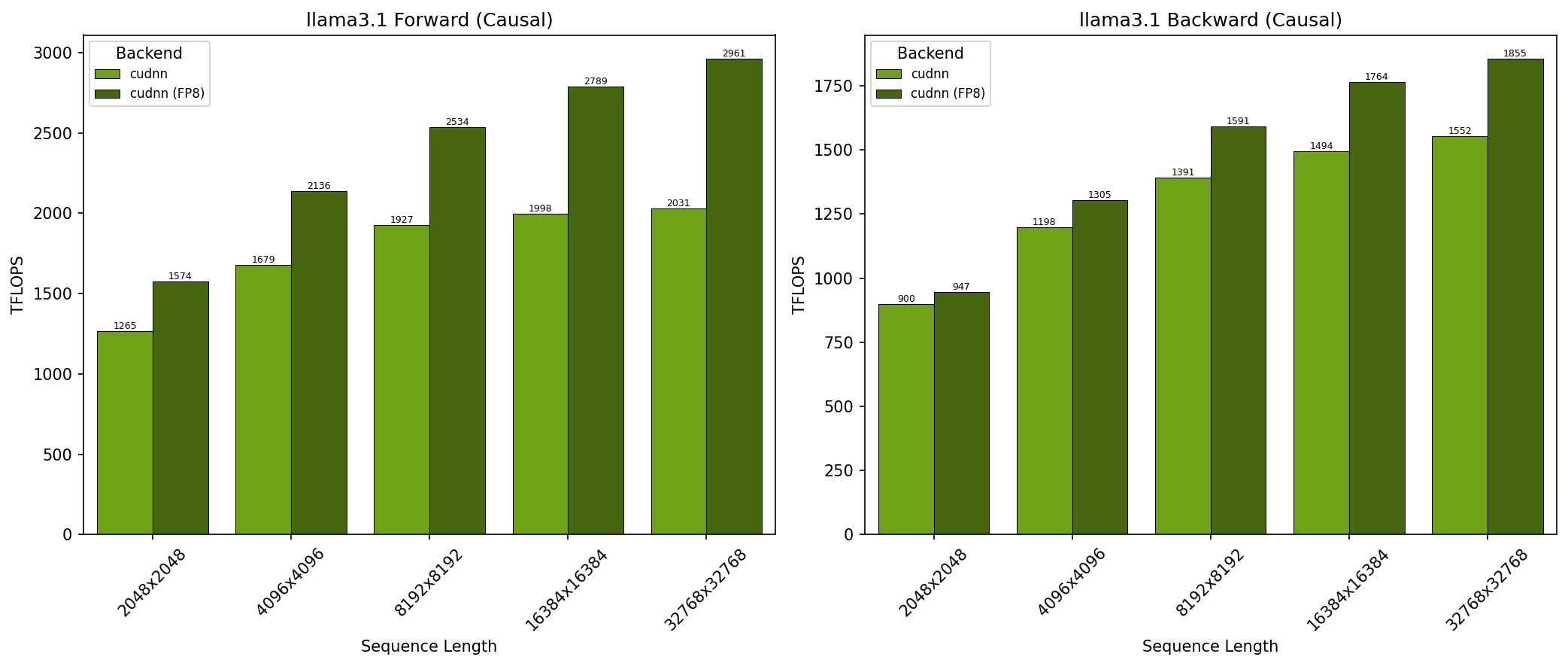
- SDPA 参数:batch=1; num_q_heads=64; num_kv_heads=8; head_dim=128; is_causal=True
- x 轴显示序列长度
- 结果在 NVIDIA GB300 GPU 上获得
GB300 - Llama 3.1 非因果注意力 (no_mask)
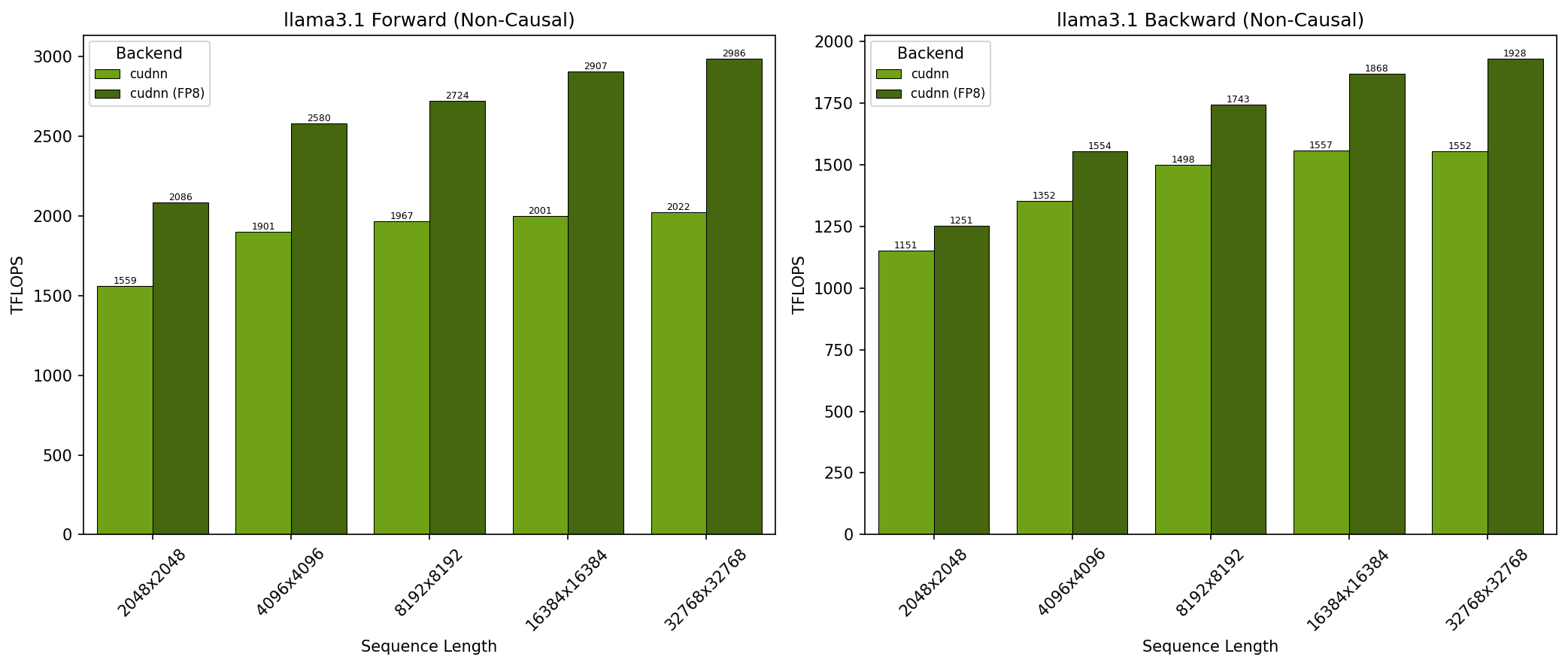
- SDPA 参数:batch=1; num_q_heads=64; num_kv_heads=8; head_dim=128; is_causal=False
- x 轴显示序列长度
- 结果在 NVIDIA GB300 GPU 上获得
GB300 - DeepSeek V3 因果注意力 (top_left)
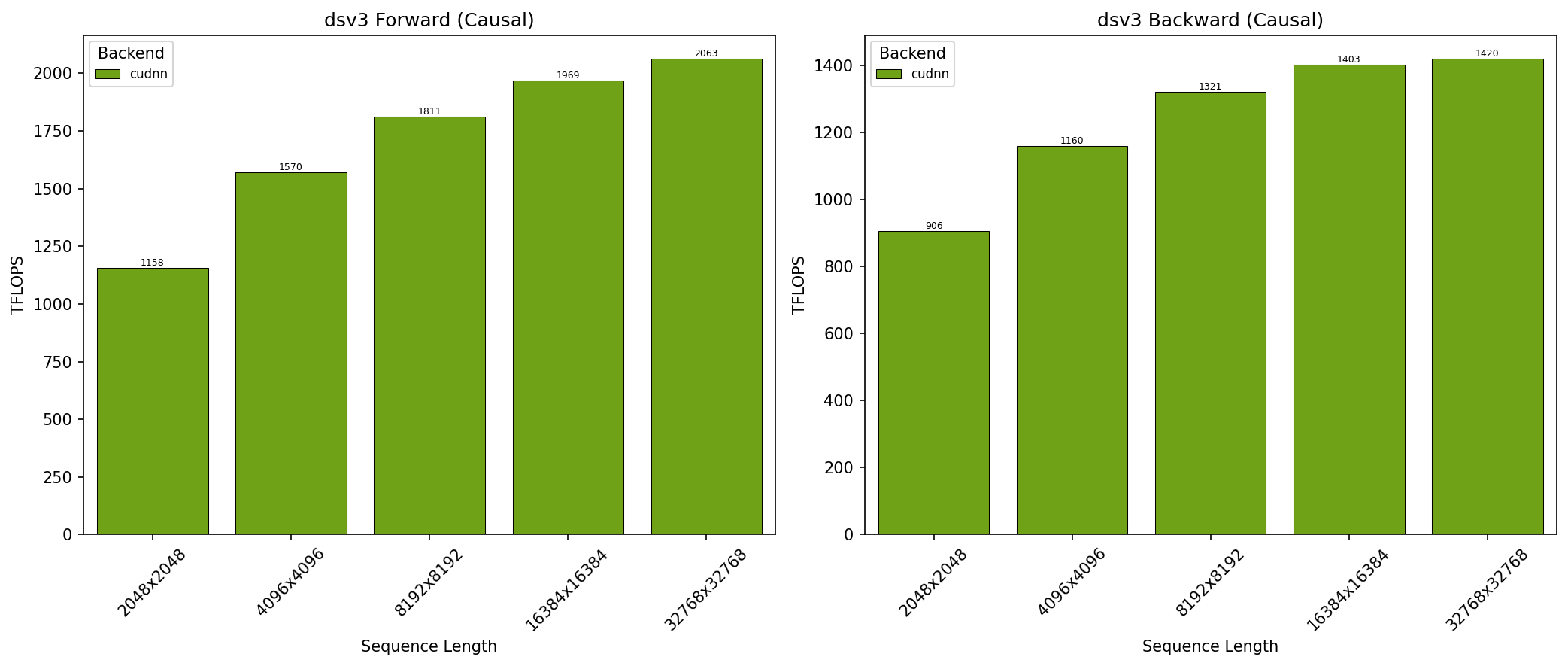
- SDPA 参数:batch=1; num_q_heads=128; num_kv_heads=128; head_dim_qk=192; head_dim_vo=128; is_causal=True
- x 轴显示序列长度
- 结果在 NVIDIA GB300 GPU 上获得
安装
🐍 Python
最简单的方式是通过 pip 安装:
pip install nvidia_cudnn_frontend
要求:
* Python 3.8+
* NVIDIA 驱动和 CUDA 工具包
⚙️ C++ (仅头文件)
由于 C++ API 是仅头文件的,集成非常简便。只需在您的编译单元中包含头文件:
#include <cudnn_frontend.h>
请确保您的包含路径指向此仓库的 include/ 目录。
从源码构建
如果您想从源码构建 Python 绑定或运行 C++ 示例:
1. 依赖项
* python-dev (例如,apt-get install python-dev)
* requirements.txt 中列出的依赖项 (pip install -r requirements.txt)
2. Python 源码构建
pip install -v git+https://github.com/NVIDIA/cudnn-frontend.git
可以使用环境变量 CUDAToolkit_ROOT 和 CUDNN_PATH 来覆盖默认路径。
3. C++ 示例构建
mkdir build && cd build
cmake -DCUDNN_PATH=/path/to/cudnn -DCUDAToolkit_ROOT=/path/to/cuda ../
cmake --build . -j16
./bin/samples
文档与示例
- 开发者指南: 官方 NVIDIA 文档
- C++ 示例: 查看
samples/cpp获取全面的使用示例。 - Python 示例: 查看
samples/python获取 Python 风格的实现。
🤝 贡献
我们热忱欢迎贡献!无论是修复错误、改进文档还是优化我们的新开源内核,您的帮助都能让 cuDNN 对每个人变得更好。
- 查看贡献指南了解详情。
- Fork 仓库并创建您的分支。
- 提交拉取请求。
调试
要查看执行流程并调试问题,可以通过环境变量启用日志记录:
# 输出到 stdout
export CUDNN_FRONTEND_LOG_INFO=1
export CUDNN_FRONTEND_LOG_FILE=stdout
# 输出到文件
export CUDNN_FRONTEND_LOG_INFO=1
export CUDNN_FRONTEND_LOG_FILE=execution_log.txt
或者,您也可以通过 cudnn_frontend::isLoggingEnabled() 以编程方式控制日志记录。
许可证
本项目采用 MIT 许可证。