OA0 ›
代码 ›
Qwen2.5-VL — 通义团队推出的多模态理解模型代码库
Qwen2.5-VL — 通义团队推出的多模态理解模型代码库
thirteen · 2026-01-05 17:25:28 · 65 次点击 · 0 条评论Qwen3-VL

💜 Qwen Chat | 🤗 Hugging Face | 🤖 ModelScope | 📑 博客 | 📚 Cookbooks | 📑 论文
🖥️ 演示 | 💬 微信 | 🫨 Discord | 📑 API | 🖥️ PAI-DSW
{kind=link}

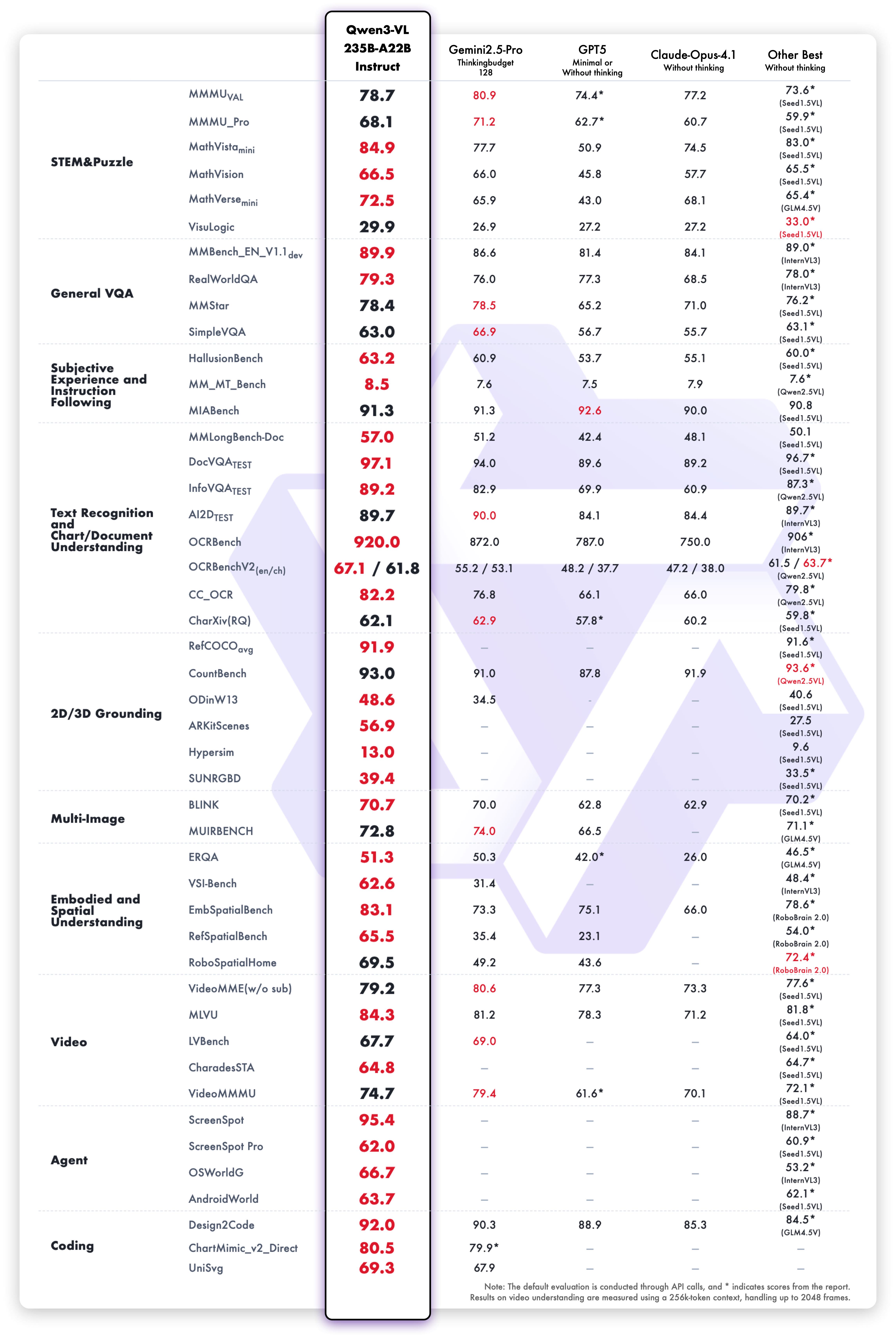
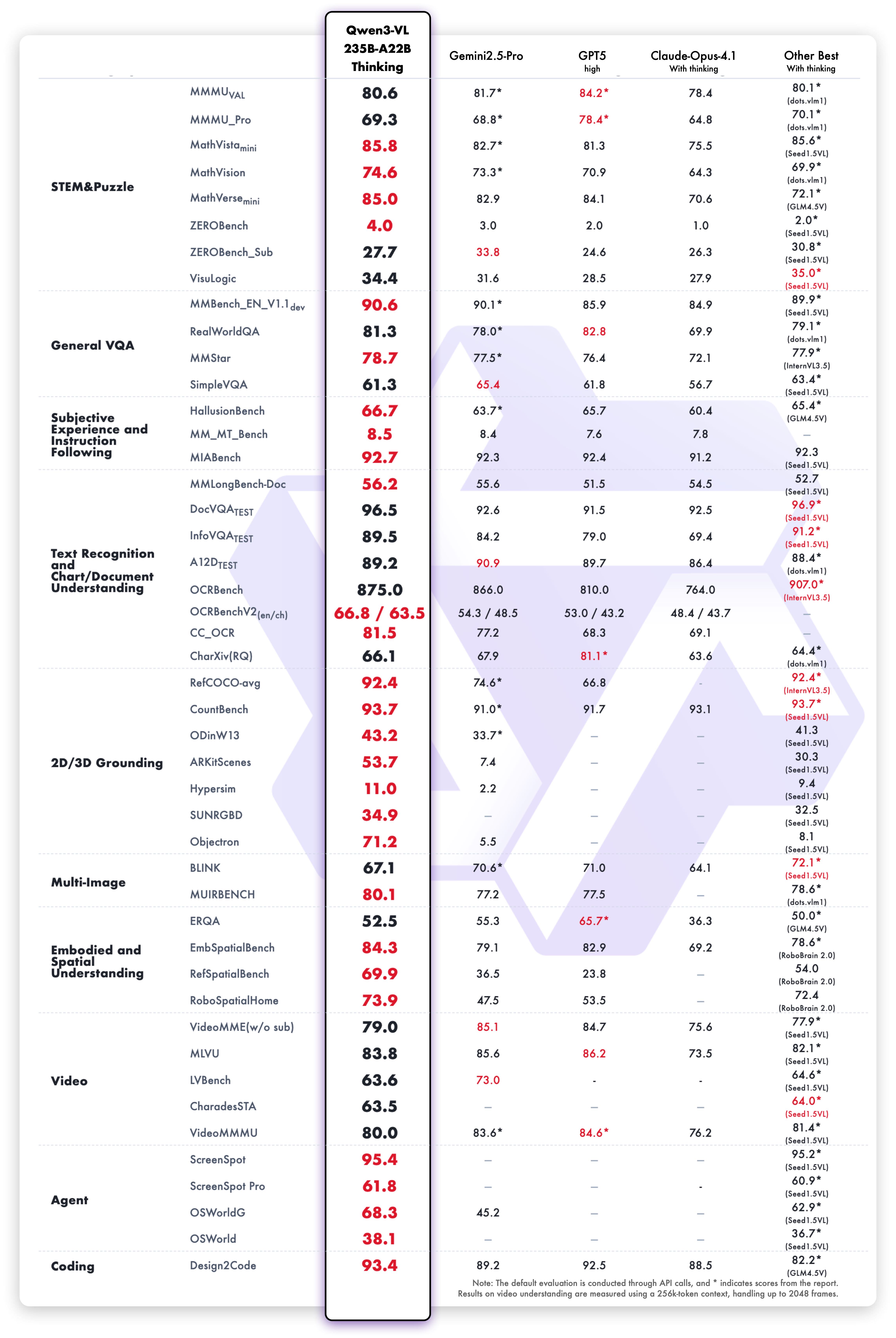
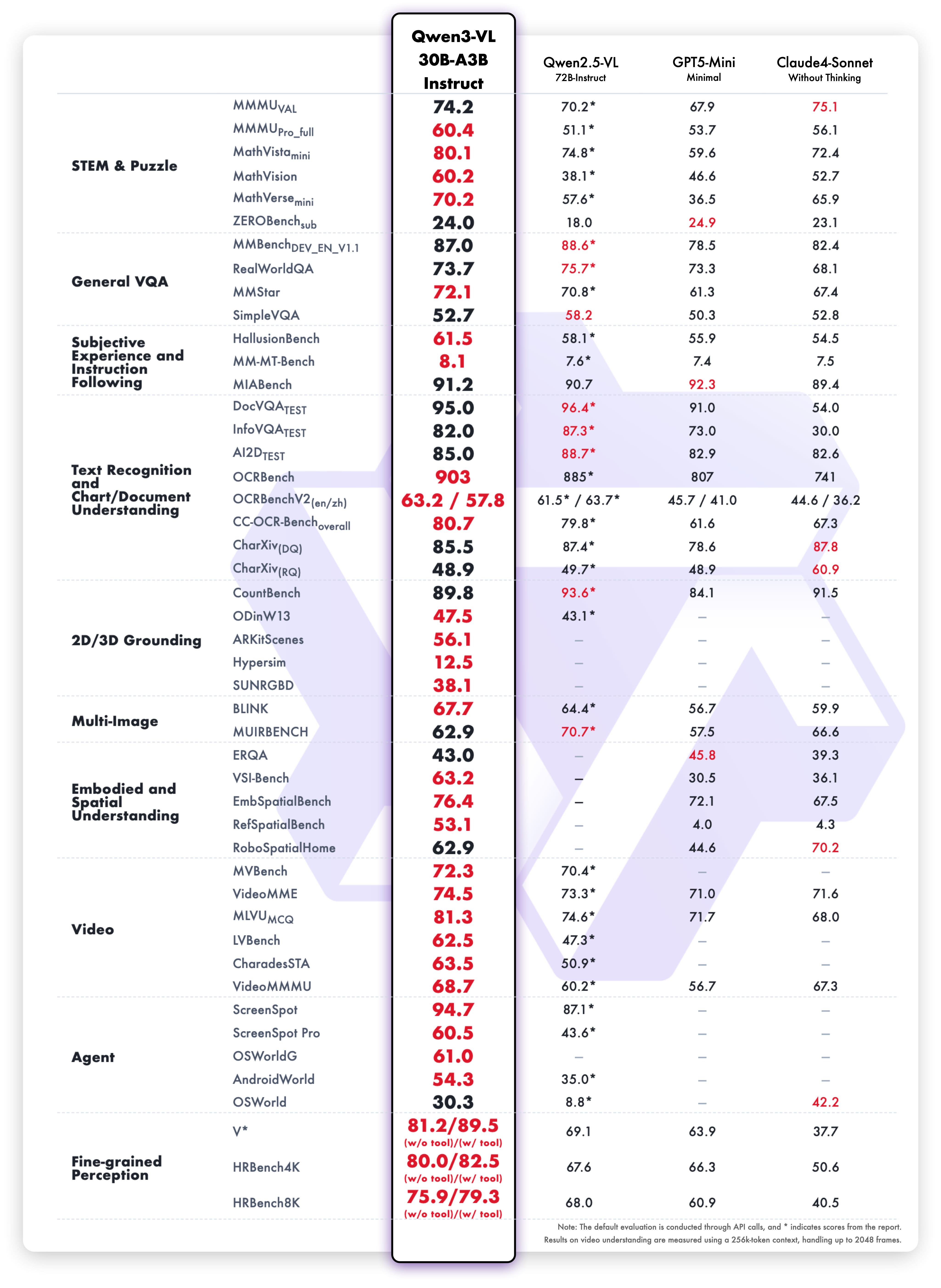
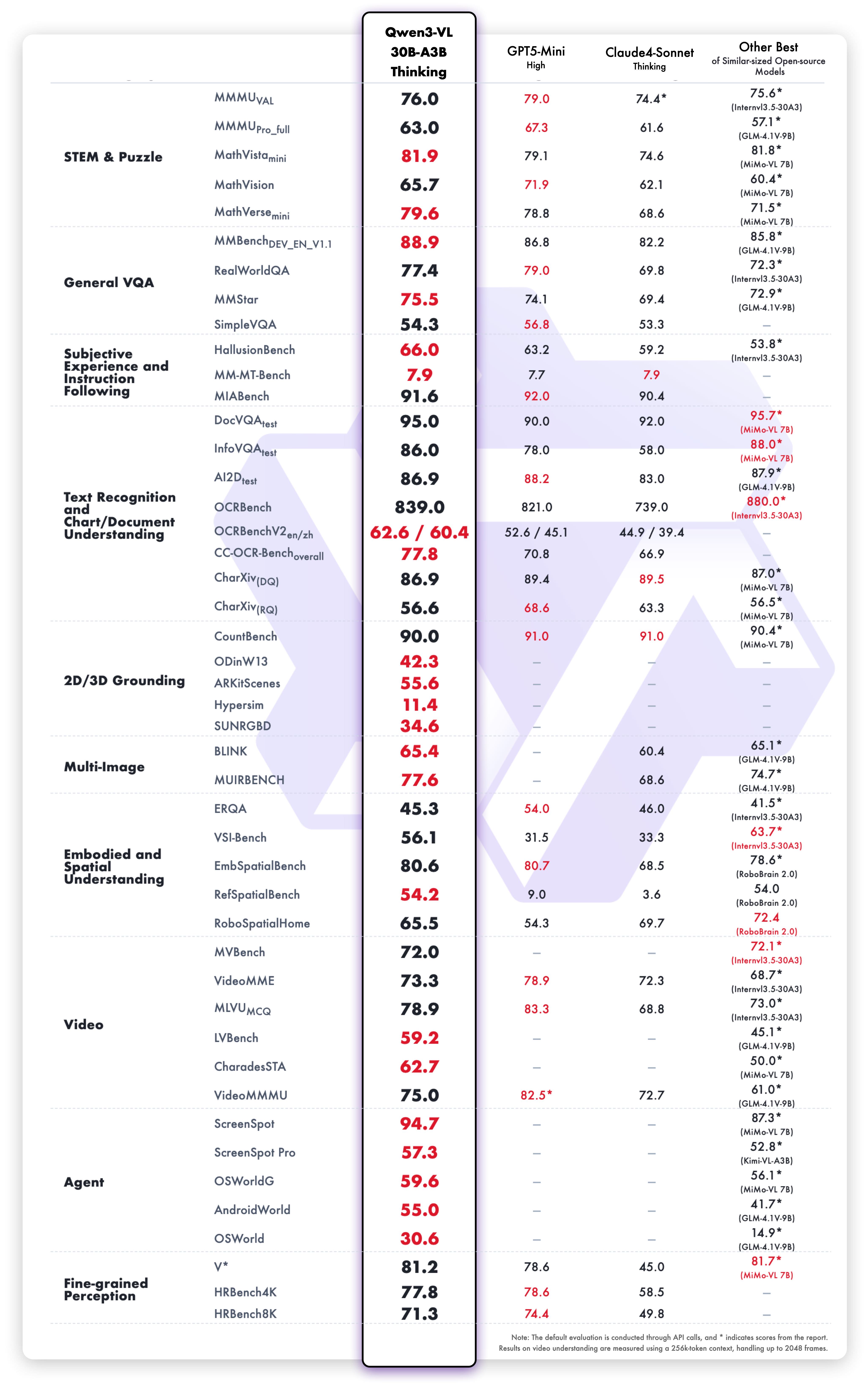
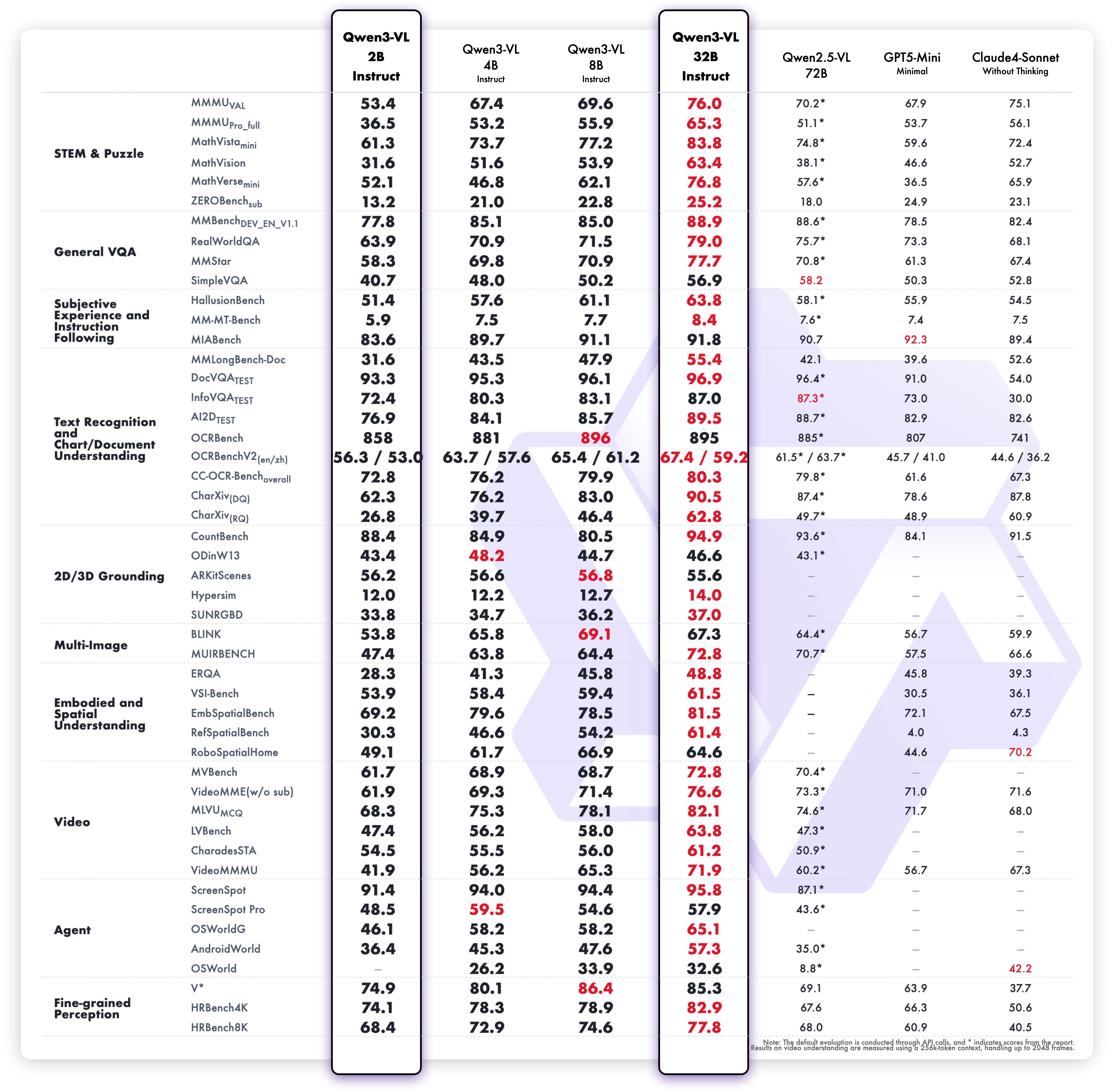
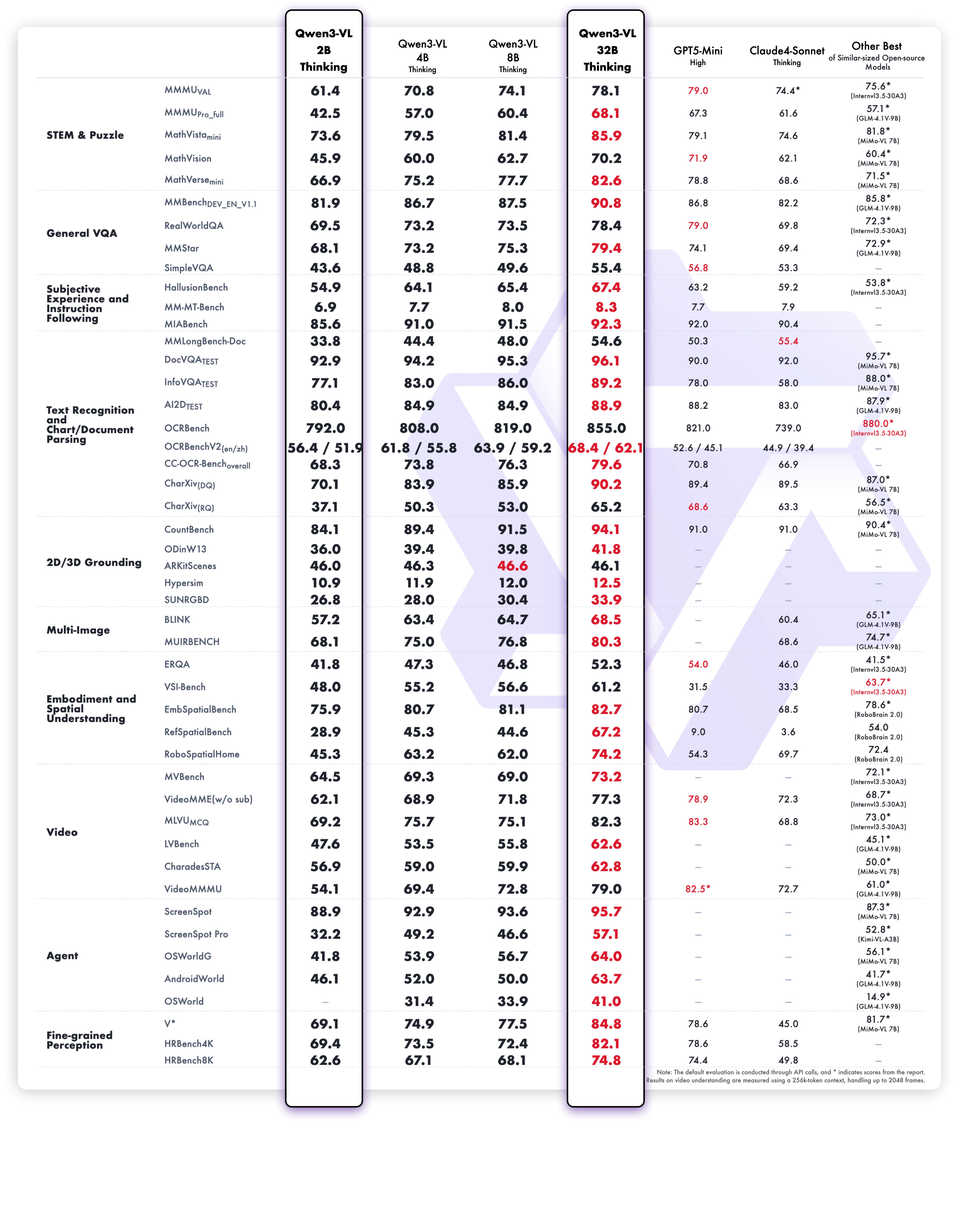
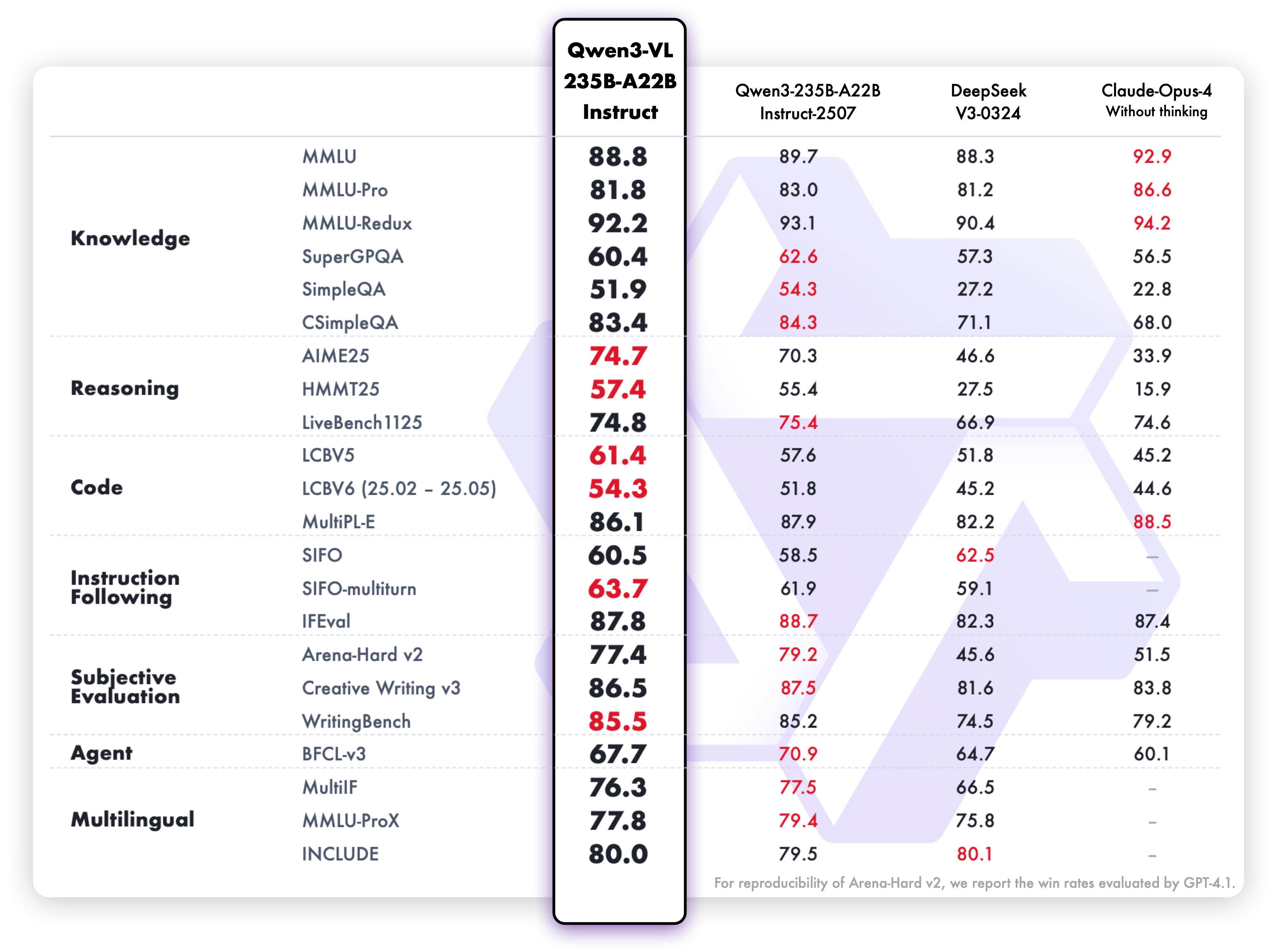
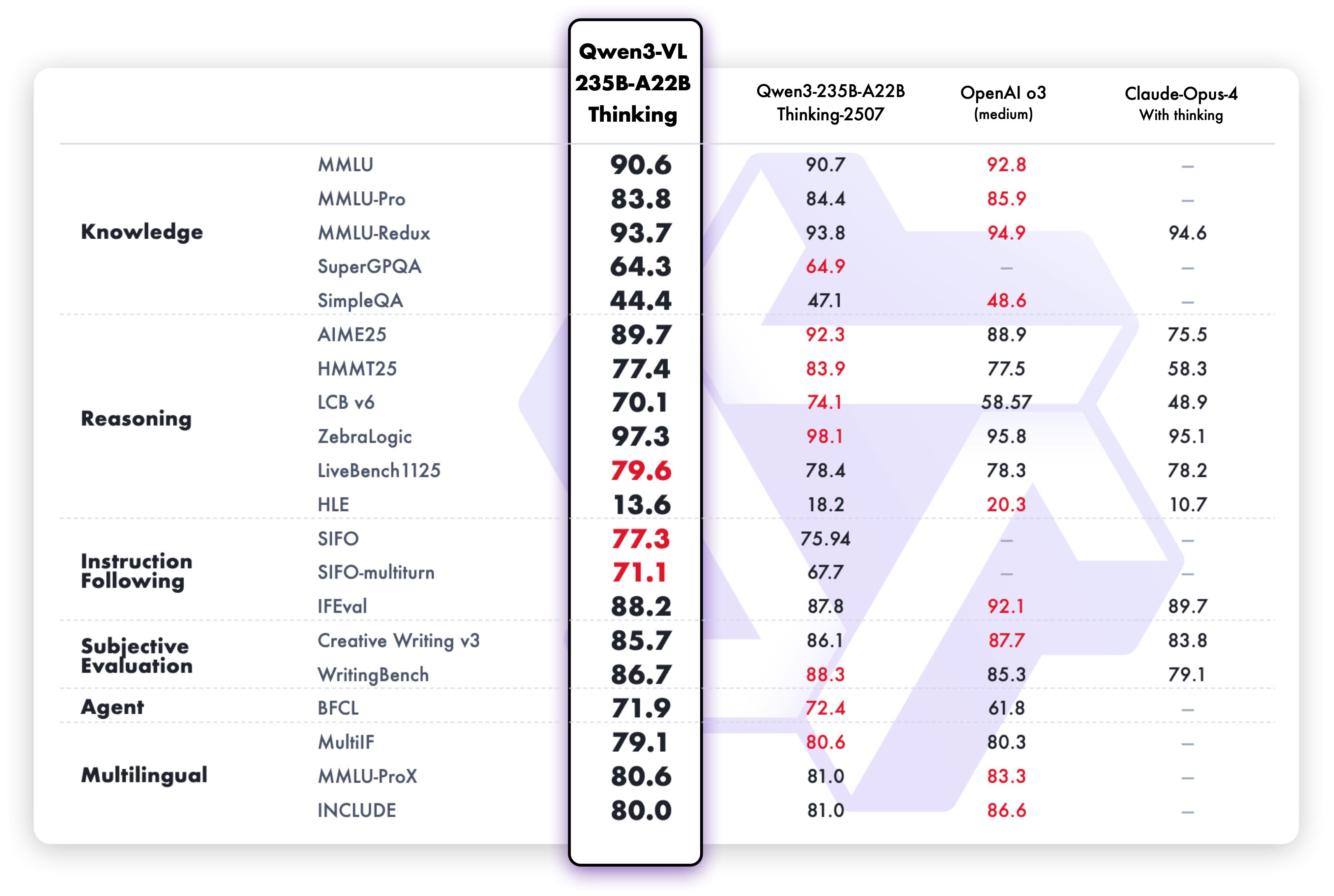
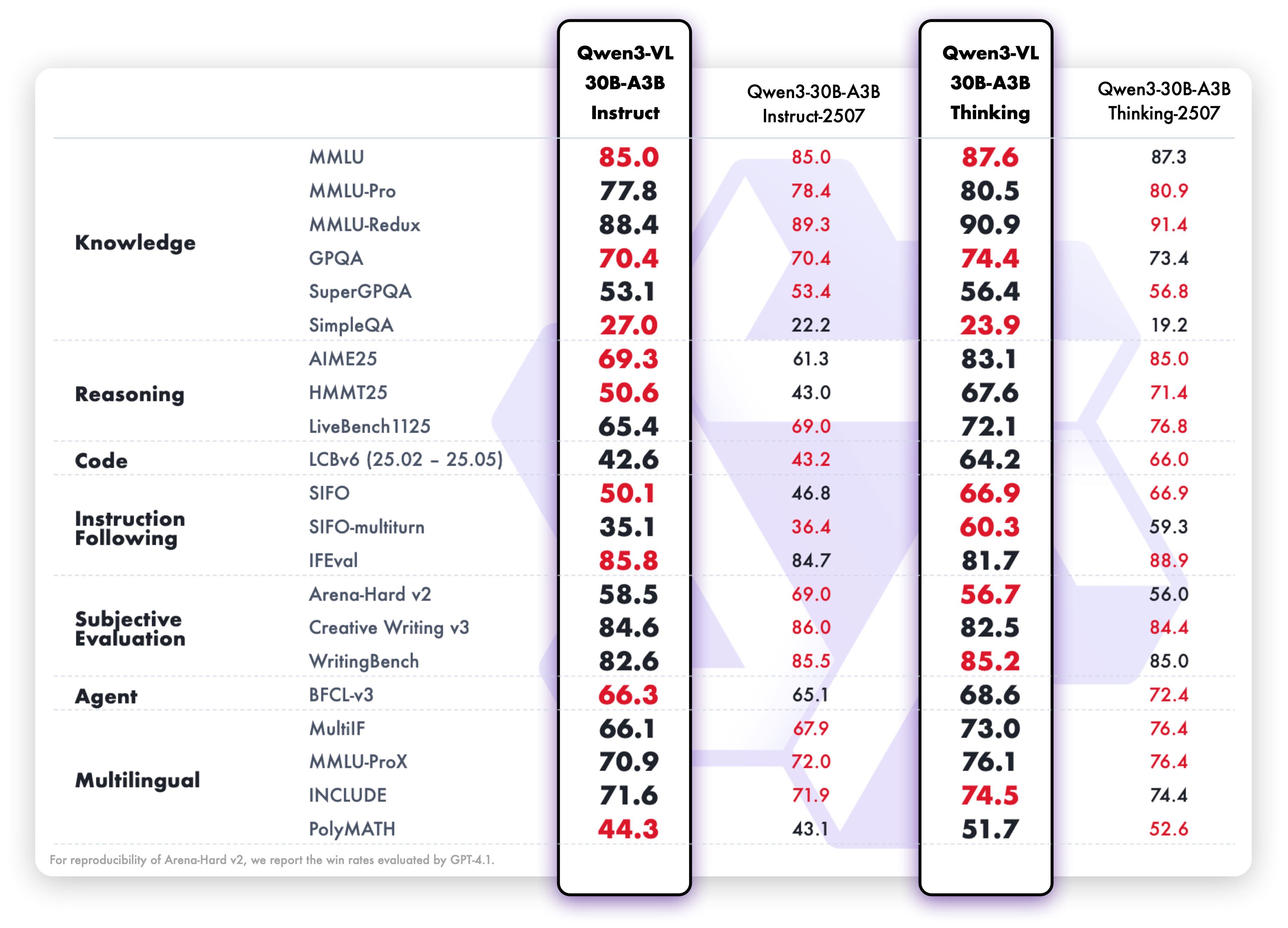
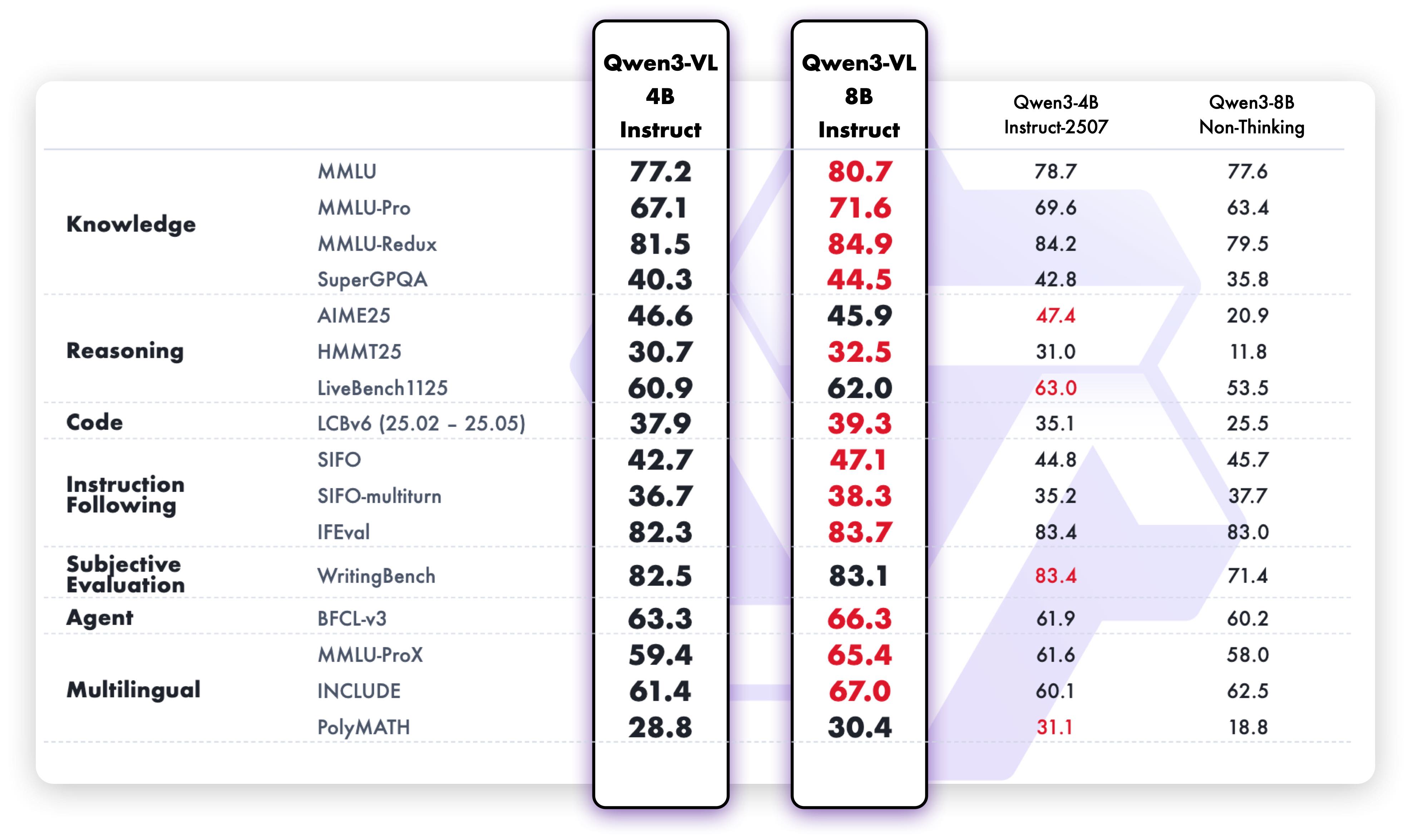
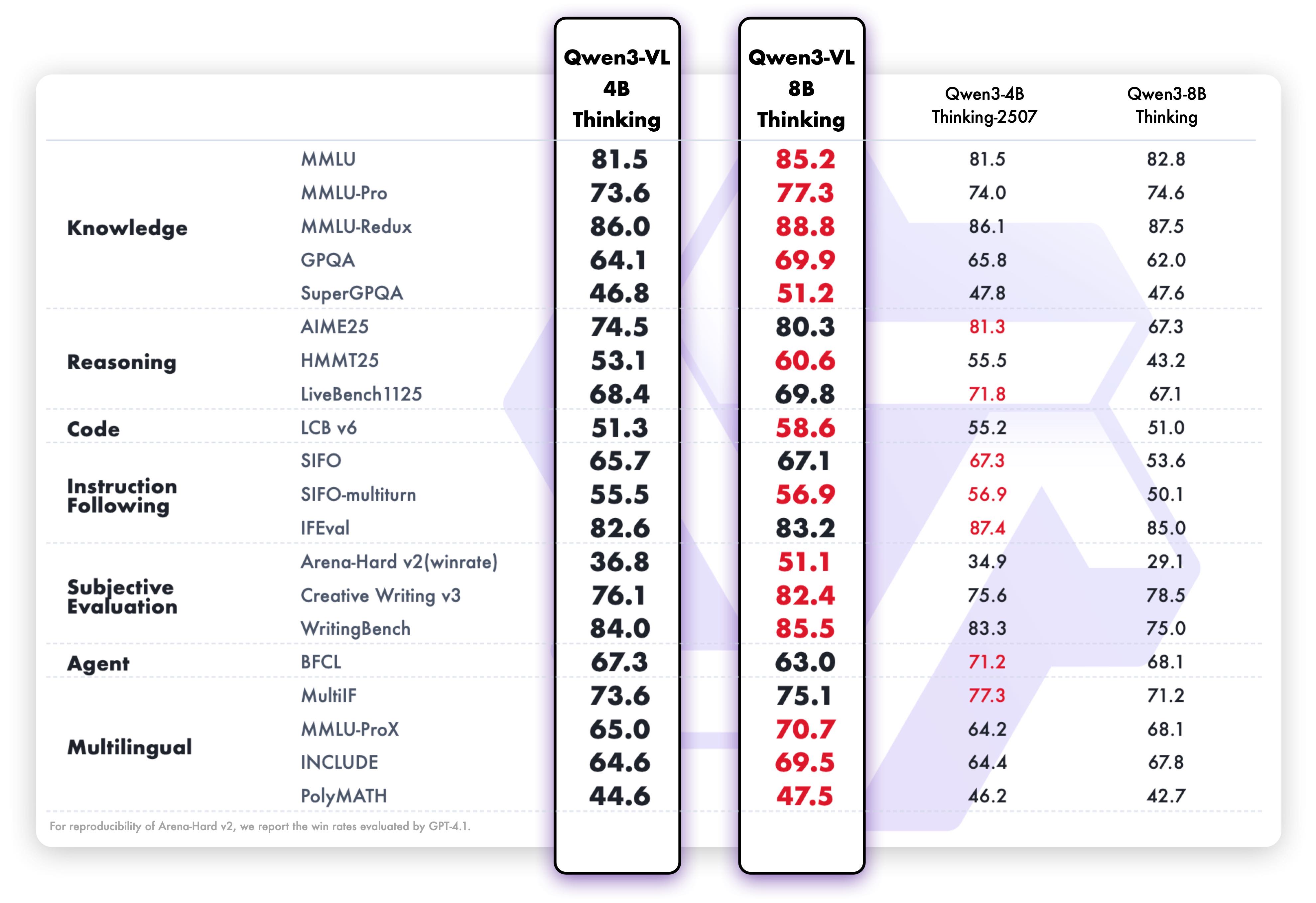
1. **Interleaved-MRoPE**:通过鲁棒的位置编码,在时间、宽度和高度维度上进行全频率分配,增强了长序列视频推理能力。 2. **DeepStack**:融合多级 ViT 特征,以捕捉细粒度细节并锐化图像-文本对齐。 3. **文本-时间戳对齐**:超越 T-RoPE,实现精确的、基于时间戳的事件定位,以增强视频时序建模。 ## 动态 * 2025.11.27:我们发布了 [**Qwen3-VL 论文**](https://arxiv.org/pdf/2511.21631),其中介绍了 Qwen3-VL 的许多技术细节,希望对大家有所帮助。 * 2025.10.21:我们发布了 **Qwen3-VL-2B** ([Instruct](https://huggingface.co/Qwen/Qwen3-VL-2B-Instruct)/[Thinking](https://huggingface.co/Qwen/Qwen3-VL-2B-Thinking)) 和 **Qwen3-VL-32B** ([Instruct](https://huggingface.co/Qwen/Qwen3-VL-32B-Instruct)/[Thinking](https://huggingface.co/Qwen/Qwen3-VL-32B-Thinking))。欢迎体验! * 2025.10.15:我们发布了 **Qwen3-VL-4B** ([Instruct](https://huggingface.co/Qwen/Qwen3-VL-4B-Instruct)/[Thinking](https://huggingface.co/Qwen/Qwen3-VL-4B-Thinking)) 和 **Qwen3-VL-8B** ([Instruct](https://huggingface.co/Qwen/Qwen3-VL-8B-Instruct)/[Thinking](https://huggingface.co/Qwen/Qwen3-VL-8B-Thinking))。欢迎体验! * 2025.10.4:我们发布了 [Qwen3-VL-30B-A3B-Instruct](https://huggingface.co/Qwen/Qwen3-VL-30B-A3B-Instruct) 和 [Qwen3-VL-30B-A3B-Thinking](https://huggingface.co/Qwen/Qwen3-VL-30B-A3B-Thinking)。同时,我们也发布了 Qwen3-VL 模型的 FP8 版本——可在我们的 [HuggingFace 集合](https://huggingface.co/collections/Qwen/qwen3-vl-68d2a7c1b8a8afce4ebd2dbe) 和 [ModelScope 集合](https://modelscope.cn/collections/Qwen3-VL-5c7a94c8cb144b) 中找到。 * 2025.09.23:我们发布了 [Qwen3-VL-235B-A22B-Instruct](https://huggingface.co/Qwen/Qwen3-VL-235B-A22B-Instruct) 和 [Qwen3-VL-235B-A22B-Thinking](https://huggingface.co/Qwen/Qwen3-VL-235B-A22B-Thinking)。更多详情,请查看我们的 [博客](https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef&from=research.latest-advancements-list)! * 2025.04.08:我们提供了用于微调 Qwen2-VL 和 Qwen2.5-VL 的 [代码](https://github.com/QwenLM/Qwen2.5-VL/tree/main/qwen-vl-finetune)。 * 2025.03.25:我们发布了 [Qwen2.5-VL-32B](https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct)。它更智能,其回答也更符合人类偏好。更多详情,请查看我们的 [博客](https://qwenlm.github.io/blog/qwen2.5-vl-32b/)! * 2025.02.20:我们发布了 [Qwen2.5-VL 技术报告](https://arxiv.org/abs/2502.13923)。同时,我们还发布了 Qwen2.5-VL 三个不同尺寸的 AWQ 量化模型:[3B](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct-AWQ)、[7B](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct-AWQ) 和 [72B](https://huggingface.co/Qwen/Qwen2.5-VL-72B-Instruct-AWQ)。 * 2025.01.28:我们发布了 [Qwen2.5-VL 系列](https://huggingface.co/Qwen)。更多详情,请查看我们的 [博客](https://qwenlm.github.io/blog/qwen2.5-vl/)! * 2024.12.25:我们发布了 [QvQ-72B-Preview](https://huggingface.co/Qwen/QVQ-72B-Preview)。QvQ-72B-Preview 是一个实验性研究模型,专注于增强视觉推理能力。更多详情,请查看我们的 [博客](https://qwenlm.github.io/blog/qvq-72b-preview/)! * 2024.09.19:指令调优的 [Qwen2-VL-72B 模型](https://huggingface.co/Qwen/Qwen2-VL-72B-Instruct) 及其量化版本 [[AWQ](https://huggingface.co/Qwen/Qwen2-VL-72B-Instruct-AWQ), [GPTQ-Int4](https://huggingface.co/Qwen/Qwen2-VL-72B-Instruct-GPTQ-Int4), [GPTQ-Int8](https://huggingface.co/Qwen/Qwen2-VL-72B-Instruct-GPTQ-Int8)] 现已可用。同时,我们也发布了 [Qwen2-VL 论文](https://arxiv.org/pdf/2409.12191)。 * 2024.08.30:我们发布了 [Qwen2-VL 系列](https://huggingface.co/collections/Qwen/qwen2-vl-66cee7455501d7126940800d)。2B 和 7B 模型现已可用,开源的 72B 模型即将推出。更多详情,请查看我们的 [博客](https://qwenlm.github.io/blog/qwen2-vl/)! ## 性能 ### 视觉任务