OA0 ›
代码 ›
KTransformers — 针对本地大模型推理优化的高性能框架
KTransformers — 针对本地大模型推理优化的高性能框架
pulse · 2026-01-31 05:22:25 · 57 次点击 · 0 条评论🎯 概述
KTransformers 是一个专注于通过 CPU-GPU 异构计算实现大语言模型高效推理与微调的研究项目。该项目已演变为两个核心模块:kt-kernel 和 kt-sft。
🔥 更新日志
- 2026年2月13日: 支持 MiniMax-M2.5 Day0! (教程)
- 2026年2月12日: 支持 GLM-5 Day0! (教程)
- 2026年1月27日: 支持 Kimi-K2.5 Day0! (教程) (微调教程)
- 2026年1月22日: 支持 CPU-GPU 专家调度、原生 BF16 和 FP8 逐通道精度 以及 AutoDL 统一微调与推理
- 2025年12月24日: 支持原生 MiniMax-M2.1 推理。 (教程)
- 2025年12月22日: 支持使用 LLaMA-Factory 进行 RL-DPO 微调。 (教程)
- 2025年12月5日: 支持原生 Kimi-K2-Thinking 推理 (教程)
- 2025年11月6日: 支持 Kimi-K2-Thinking 推理 (教程) 和微调 (教程)
- 2025年11月4日: KTransformers 微调 × LLaMA-Factory 集成。 (教程)
- 2025年10月27日: 支持 Ascend NPU。 (教程)
- 2025年10月10日: 集成至 SGLang。 (路线图, 博客)
- 2025年9月11日: 支持 Qwen3-Next。 (教程)
- 2025年9月5日: 支持 Kimi-K2-0905。 (教程)
- 2025年7月26日: 支持 SmallThinker 和 GLM4-MoE。 (教程)
- 2025年7月11日: 支持 Kimi-K2。 (教程)
- 2025年6月30日: 支持 3 层(GPU-CPU-磁盘)前缀缓存 复用。
- 2025年5月14日: 支持 Intel Arc GPU (教程)。
- 2025年4月29日: 支持 AMX-Int8、AMX-BF16 和 Qwen3MoE (教程)
- 2025年4月9日: 实验性支持 LLaMA 4 模型 (教程)。
- 2025年4月2日: 支持多并发。 (教程)。
- 2025年3月15日: 支持 AMD GPU 上的 ROCm (教程)。
- 2025年3月5日: 支持 unsloth 1.58/2.51 位权重和 IQ1_S/FP8 混合 权重。支持在 24GB VRAM 下为 DeepSeek-V3 和 R1 实现 139K 更长上下文。
- 2025年2月25日: 为 DeepSeek-V3 和 R1 支持 FP8 GPU 内核;更长上下文。
- 2025年2月15日: 更长上下文(24GB VRAM 下从 4K 到 8K)& 略微提速(+15%,最高 16 Tokens/s),更新 文档 和 在线书籍。
- 2025年2月10日: 支持在单卡(24GB VRAM)/多卡和 382G DRAM 上运行 Deepseek-R1 和 V3,速度提升最高达 3~28 倍。详细案例和复现教程见此处。
- 2024年8月28日: 将 DeepseekV2 所需 VRAM 从 21G 降至 11G。
- 2024年8月15日: 更新了详细的注入和多 GPU 教程。
- 2024年8月14日: 支持 llamfile 作为线性后端。
- 2024年8月12日: 支持多 GPU;支持新模型:mixtral 8*7B 和 8*22B;支持 GPU 上的 q2k、q3k、q5k 反量化。
- 2024年8月9日: 支持原生 Windows。
📦 核心模块
🚀 kt-kernel - 高性能推理内核
面向异构 LLM 推理的 CPU 优化内核操作。
核心特性:
- AMX/AVX 加速:针对 INT4/INT8 量化推理优化的 Intel AMX 和 AVX512/AVX2 内核
- MoE 优化:具有 NUMA 感知内存管理的高效混合专家模型推理
- 量化支持:CPU 端 INT4/INT8 量化权重,GPU 端 GPTQ 支持
- 易于集成:为 SGLang 等框架提供简洁的 Python API
快速开始:
cd kt-kernel
pip install .
使用场景:
- 大型 MoE 模型的 CPU-GPU 混合推理
- 与 SGLang 集成用于生产环境服务
- 异构专家放置(热专家在 GPU,冷专家在 CPU)
性能示例:
| 模型 | 硬件配置 | 总吞吐量 | 输出吞吐量 |
|-------|------------------------|------------------|-------------------|
| DeepSeek-R1-0528 (FP8) | 8×L20 GPU + Xeon Gold 6454S | 227.85 tokens/s | 87.58 tokens/s (8路并发) |
👉 完整文档 →
🎓 kt-sft - 微调框架
KTransformers × LLaMA-Factory 集成,用于超大型 MoE 模型微调。
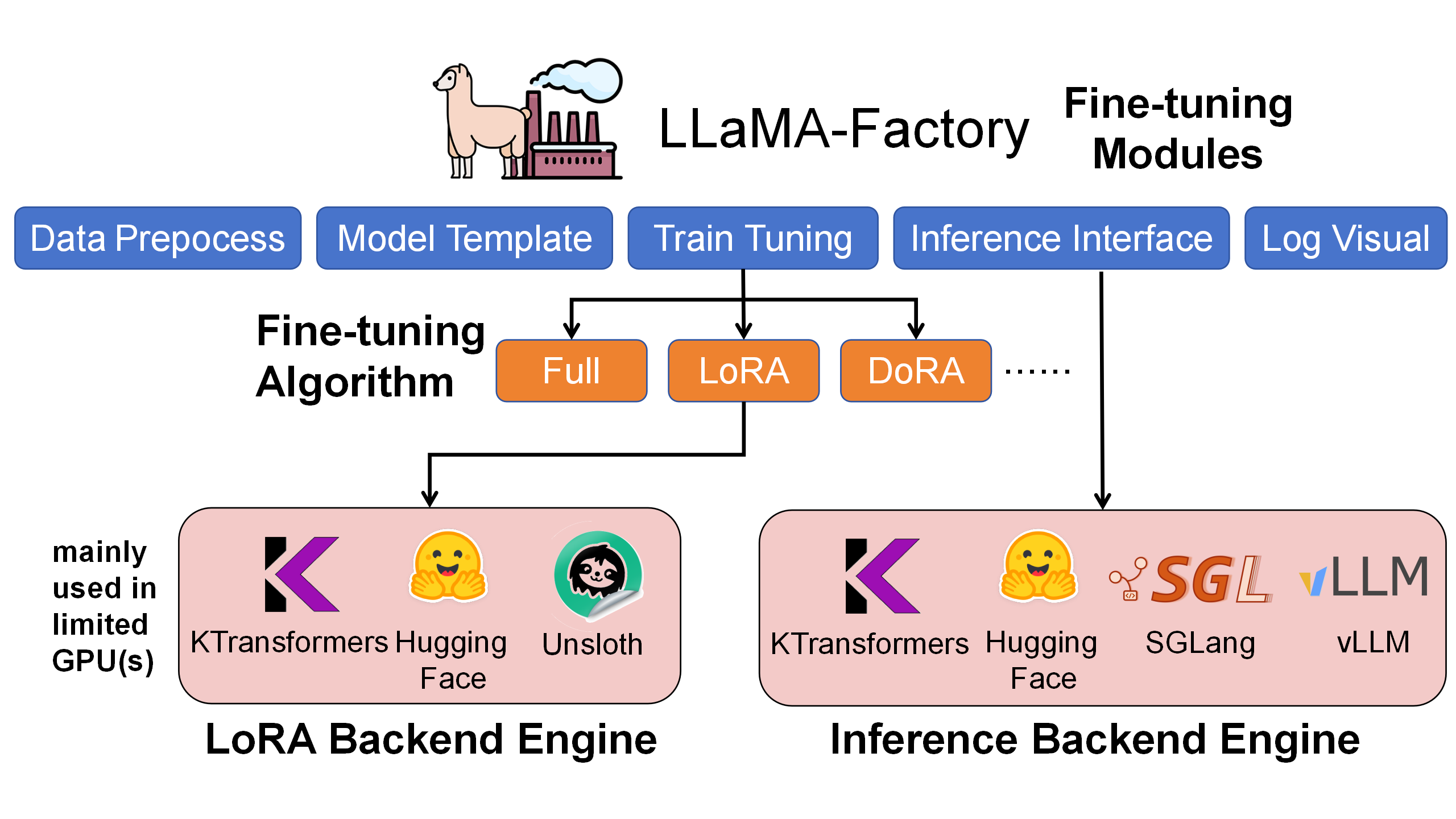
核心特性:
- 资源高效:仅需 70GB GPU 内存 + 1.3TB RAM 即可微调 671B 的 DeepSeek-V3
- LoRA 支持:支持异构加速的完整 LoRA 微调
- LLaMA-Factory 集成:与流行的微调框架无缝集成
- 生产就绪:支持对话、批量推理和指标评估
性能示例:
| 模型 | 配置 | 吞吐量 | GPU 内存 |
|---|---|---|---|
| DeepSeek-V3 (671B) | LoRA + AMX | ~40 tokens/s | 70GB (多 GPU) |
| DeepSeek-V2-Lite (14B) | LoRA + AMX | ~530 tokens/s | 6GB |
快速开始:
cd kt-sft
# 按照 kt-sft/README.md 安装环境
USE_KT=1 llamafactory-cli train examples/train_lora/deepseek3_lora_sft_kt.yaml
👉 完整文档 →
🔥 引用
如果您在研究中使用了 KTransformers,请引用我们的论文:
@inproceedings{10.1145/3731569.3764843,
title = {KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models},
author = {Chen, Hongtao and Xie, Weiyu and Zhang, Boxin and Tang, Jingqi and Wang, Jiahao and Dong, Jianwei and Chen, Shaoyuan and Yuan, Ziwei and Lin, Chen and Qiu, Chengyu and Zhu, Yuening and Ou, Qingliang and Liao, Jiaqi and Chen, Xianglin and Ai, Zhiyuan and Wu, Yongwei and Zhang, Mingxing},
booktitle = {Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles},
year = {2025}
}
👥 贡献者与团队
由以下团队开发和维护:
- 清华大学 MADSys Lab
- Approaching.AI
- 9#AISoft
- 社区贡献者
我们欢迎贡献!请随时提交 Issue 和 Pull Request。
💬 社区与支持
- GitHub Issues:报告问题或请求功能
- 微信群:见 archive/WeChatGroup.png
{kind=link}
📦 KT 原始代码
原始的集成 KTransformers 框架已归档至 archive/ 目录以供参考。项目现在专注于上述两个核心模块,以实现更好的模块化和可维护性。
有关包含完整快速入门指南和示例的原始文档,请参阅:
- archive/README.md (英文)
- archive/README_ZH.md (中文)