简介
LMDeploy 是一个由 MMRazor 和 MMDeploy 团队开发的用于压缩、部署和服务大语言模型的工具包。它具有以下核心特性:
-
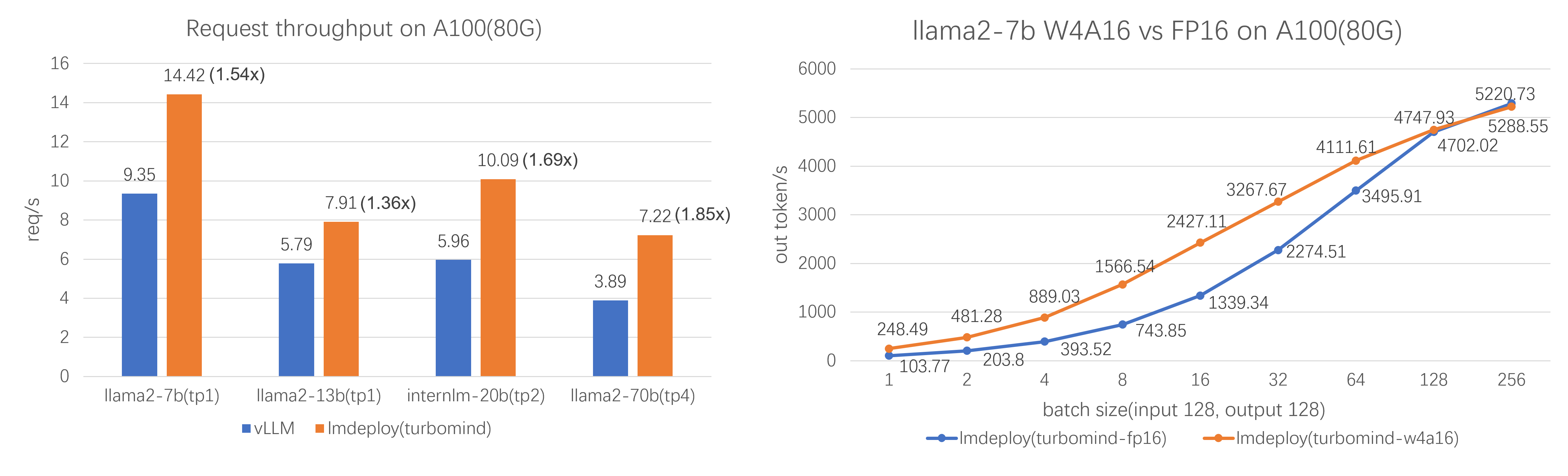
高效推理:LMDeploy 通过引入持久批处理(又称连续批处理)、分块 KV 缓存、动态拆分与融合、张量并行、高性能 CUDA 内核等关键技术,实现了比 vLLM 高达 1.8 倍的请求吞吐量。
-
有效量化:LMDeploy 支持权重量化和 k/v 量化,4 位推理性能比 FP16 高 2.4 倍。量化质量已通过 OpenCompass 评估验证。
-
便捷的分布式服务:利用请求分发服务,LMDeploy 可以轻松高效地部署跨多机多卡的多模型服务。
-
出色的兼容性:LMDeploy 支持 KV Cache 量化、AWQ 和 自动前缀缓存 同时使用。
性能
支持的模型
|
大语言模型
|
视觉语言模型
|
- Llama (7B - 65B)
- Llama2 (7B - 70B)
- Llama3 (8B, 70B)
- Llama3.1 (8B, 70B)
- Llama3.2 (1B, 3B)
- InternLM (7B - 20B)
- InternLM2 (7B - 20B)
- InternLM3 (8B)
- InternLM2.5 (7B)
- Qwen (1.8B - 72B)
- Qwen1.5 (0.5B - 110B)
- Qwen1.5 - MoE (0.5B - 72B)
- Qwen2 (0.5B - 72B)
- Qwen2-MoE (57BA14B)
- Qwen2.5 (0.5B - 32B)
- Qwen3, Qwen3-MoE
- Qwen3-Next(80B)
- Baichuan (7B)
- Baichuan2 (7B-13B)
- Code Llama (7B - 34B)
- ChatGLM2 (6B)
- GLM-4 (9B)
- GLM-4-0414 (9B, 32B)
- CodeGeeX4 (9B)
- YI (6B-34B)
- Mistral (7B)
- DeepSeek-MoE (16B)
- DeepSeek-V2 (16B, 236B)
- DeepSeek-V2.5 (236B)
- DeepSeek-V3 (685B)
- DeepSeek-V3.2 (685B)
- Mixtral (8x7B, 8x22B)
- Gemma (2B - 7B)
- StarCoder2 (3B - 15B)
- Phi-3-mini (3.8B)
- Phi-3.5-mini (3.8B)
- Phi-3.5-MoE (16x3.8B)
- Phi-4-mini (3.8B)
- MiniCPM3 (4B)
- SDAR (1.7B-30B)
- gpt-oss (20B, 120B)
- GLM-4.7-Flash (30B)
- GLM-5 (754B)
|
- LLaVA(1.5,1.6) (7B-34B)
- InternLM-XComposer2 (7B, 4khd-7B)
- InternLM-XComposer2.5 (7B)
- Qwen-VL (7B)
- Qwen2-VL (2B, 7B, 72B)
- Qwen2.5-VL (3B, 7B, 72B)
- Qwen3-VL (2B - 235B)
- Qwen3.5 (0.8B - 397B)
- DeepSeek-VL (7B)
- DeepSeek-VL2 (3B, 16B, 27B)
- InternVL-Chat (v1.1-v1.5)
- InternVL2 (1B-76B)
- InternVL2.5(MPO) (1B-78B)
- InternVL3 (1B-78B)
- InternVL3.5 (1B-241BA28B)
- Intern-S1 (241B)
- Intern-S1-mini (8.3B)
- Intern-S1-Pro (1TB)
- Mono-InternVL (2B)
- ChemVLM (8B-26B)
- CogVLM-Chat (17B)
- CogVLM2-Chat (19B)
- MiniCPM-Llama3-V-2_5
- MiniCPM-V-2_6
- Phi-3-vision (4.2B)
- Phi-3.5-vision (4.2B)
- GLM-4V (9B)
- GLM-4.1V-Thinking (9B)
- Llama3.2-vision (11B, 90B)
- Molmo (7B-D,72B)
- Gemma3 (1B - 27B)
- Llama4 (Scout, Maverick)
|
LMDeploy 开发了两个推理引擎——TurboMind 和 PyTorch,各有侧重。前者致力于极致的推理性能优化,而后者完全使用 Python 开发,旨在降低开发者的门槛。
它们在支持的模型类型和推理数据类型上有所不同。请参考此表格了解每个引擎的能力,并选择最适合您实际需求的引擎。
快速开始 
安装
建议在 conda 环境(python 3.10 - 3.13)中使用 pip 安装 lmdeploy:
conda create -n lmdeploy python=3.10 -y
conda activate lmdeploy
pip install lmdeploy
自 v0.3.0 起,默认的预编译包基于 CUDA 12 编译。
对于 GeForce RTX 50 系列,请安装基于 CUDA 12.8 编译的 LMDeploy 预编译包:
```shell