OA0 ›
代码 ›
EmbedAnything — 面向多格式内容的高性能嵌入生成工具
EmbedAnything — 面向多格式内容的高性能嵌入生成工具
nest · 2026-02-11 07:45:47 · 57 次点击 · 0 条评论🚀 核心特性
- 无 Pytorch 依赖:易于云端部署,内存占用低。
- 高度模块化:为 RAG 选择任何向量数据库适配器,只需 ~~1 行~~ 1 个单词的代码。
- 后端支持:支持 Candle、ONNX 和云端模型。
- 多模态:支持文本源(如 PDF、txt、md)、图像(JPG)和音频(.WAV)。
- GPU 支持:支持 GPU 硬件加速。
- 分块处理:内置语义分块、延迟分块等方法。
- 向量流式处理:将文件处理、索引和推理分离到不同线程,降低延迟。
- AWS S3 存储桶:直接导入 AWS S3 存储桶文件。
- 预构建 Docker 镜像:直接拉取:
starlightsearch/embedanything-server。 - 搜索代理:展示如何使用索引进行 Searchr1 推理的示例。
💡 什么是向量流式处理
嵌入模型计算成本高且耗时。通过将文档预处理与模型推理分离,可以显著降低管道延迟并提高吞吐量。
向量流式处理将串行瓶颈转变为高效、并发的工作流。
嵌入过程与主进程分离,以保持 Rust MPSC 实现的高性能,并且由于嵌入直接保存到向量数据库,避免了内存泄漏。查看我们的博客。

🦀 为何选择 EmbedAnything
➡️ 执行速度更快。
➡️ 无 Pytorch 依赖,因此内存占用低,易于云端部署。
➡️ 真正的多线程。
➡️ 本地高效运行嵌入模型。
➡️ 内置语义分块、延迟分块等方法。
➡️ 支持多种模型:稠密、稀疏、Late-interaction、重排序器、ModernBert。
➡️ 内存管理:Rust 强制执行内存管理,防止内存泄漏和其他语言中常见的崩溃问题。
⚠️ WhichModel 已在 pretrained_hf 中弃用
🍓 过往合作
我们曾与知名企业合作,例如:
Elastic、Weaviate、SingleStore、Milvus 以及 Analytics Vidya Datahours。
欢迎联系我们进行进一步合作。
性能基准
推理速度基准
仅测量嵌入模型在 ONNX 运行时上的推理速度。代码
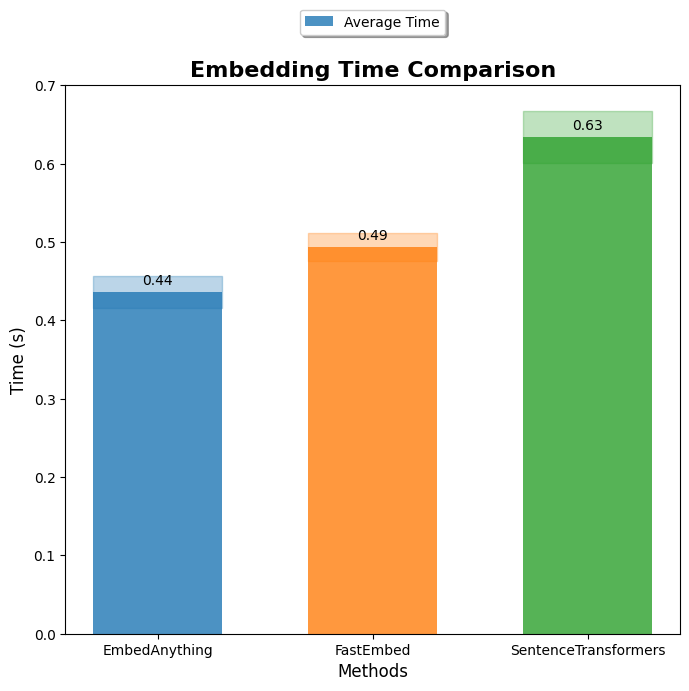
与其他框架的基准测试即将发布!!🚀
⭐ 支持的模型
我们支持 Candle 上的任何 Hugging Face 模型。同时,我们也支持 BERT 和 ColPali 的 ONNX 运行时。
如何在 Candle 上添加自定义模型:from_pretrained_hf
⚠️ WhichModel 已在 from_pretrained_hf 中弃用
import embed_anything
from embed_anything import EmbeddingModel, WhichModel, TextEmbedConfig
# 从 Hugging Face 加载自定义 BERT 模型
model = EmbeddingModel.from_pretrained_hf(
model_id="sentence-transformers/all-MiniLM-L12-v2"
)
# 配置嵌入参数
config = TextEmbedConfig(
chunk_size=1000, # 每个分块的最大字符数
batch_size=32, # 并行处理的分块数量
splitting_strategy="sentence" # 文本分割策略:"sentence"、"word" 或 "semantic"
)
# 嵌入文件(支持 PDF、TXT、MD 等)
data = embed_anything.embed_file("path/to/your/file.pdf", embedder=model, config=config)
# 访问嵌入向量和文本
for item in data:
print(f"文本: {item.text[:100]}...") # 前 100 个字符
print(f"嵌入向量维度: {len(item.embedding)}")
print(f"元数据: {item.metadata}")
print("---" * 20)
| 模型 | HF 链接 |
|---|---|
| Jina | Jina Models |
| Bert | 所有基于 Bert 的模型 |
| CLIP | openai/clip-* |
| Whisper | OpenAI Whisper 模型 |
| ColPali | starlight-ai/colpali-v1.2-merged-onnx |
| Colbert | answerdotai/answerai-colbert-small-v1, jinaai/jina-colbert-v2 等 |
| Splade | Splade 模型 及其他类似 Splade 的模型 |
| Model2Vec | model2vec, minishlab/potion-base-8M |
| Qwen3-Embedding | Qwen/Qwen3-Embedding-0.6B |
| Reranker | Jina Reranker 模型, Xenova/bge-reranker, Qwen/Qwen3-Reranker-4B |
Splade 模型(稀疏嵌入)
稀疏嵌入适用于基于关键字的检索和混合搜索场景。
import embed_anything
from embed_anything import EmbeddingModel, TextEmbedConfig
# 加载用于稀疏嵌入的 SPLADE 模型
model = EmbeddingModel.from_pretrained_hf(
model_id="prithivida/Splade_PP_en_v1"
)
# 配置嵌入过程
config = TextEmbedConfig(chunk_size=1000, batch_size=32)
# 嵌入文本文件
data = embed_anything.embed_file("test_files/document.txt", embedder=model, config=config)
# 稀疏嵌入适用于混合搜索(结合稠密和稀疏)
for item in data:
print(f"文本: {item.text}")
print(f"稀疏嵌入(非零值数量): {sum(1 for x in item.embedding if x != 0)}")
ONNX 运行时:from_pretrained_onnx
ONNX 模型提供更快的推理速度和更低的内存使用。使用 ONNXModel 枚举获取预配置模型,或提供自定义模型路径。
BERT 模型
import embed_anything
from embed_anything import EmbeddingModel, WhichModel, ONNXModel, Dtype, TextEmbedConfig
# 选项 2:从 Hugging Face 使用自定义 ONNX 模型
model = EmbeddingModel.from_pretrained_onnx(
WhichModel.Bert
model_id="onnx_model_link",
dtype=Dtype.F16 # 使用半精度以加快推理速度
)
云端嵌入模型(Cohere Embed v4)
使用云端模型获取高质量嵌入,无需本地部署模型。
import embed_anything
from embed_anything import EmbeddingModel, WhichModel
import os
# 设置您的 API 密钥
os.environ["COHERE_API_KEY"] = "your-api-key-here"
# 初始化云端模型
model = EmbeddingModel.from_pretrained_cloud(
WhichModel.CohereVision,
model_id="embed-v4.0"
)
# 像使用其他模型一样使用它
data = embed_anything.embed_file("test_files/document.pdf", embedder=model)
语义分块
语义分块通过在语义上有意义的边界处拆分文本来保留含义,而不是使用固定大小。
import embed_anything
from embed_anything import EmbeddingModel, TextEmbedConfig
# 用于生成最终嵌入向量的主嵌入模型
model = EmbeddingModel.from_pretrained_hf(
model_id="sentence-transformers/all-MiniLM-L12-v2"
)
# 用于确定分块边界的语义编码器
# 该模型分析文本以找到自然的语义断点
semantic_encoder = EmbeddingModel.from_pretrained_hf(
model_id="jinaai/jina-embeddings-v2-small-en"
)
# 配置语义分块
config = TextEmbedConfig(
chunk_size=1000, # 目标分块大小
batch_size=32, # 批处理大小
splitting_strategy="semantic", # 使用语义分割
semantic_encoder=semantic_encoder # 用于语义分析的模型
)
# 使用语义分块进行嵌入
data = embed_anything.embed_file("test_files/document.pdf", embedder=model, config=config)
# 分块将在语义上有意义的边界处拆分
for item in data:
print(f"分块: {item.text[:200]}...")
print("---" * 20)
延迟分块
延迟分块首先将文本拆分为更小的单元,然后在嵌入过程中将它们组合起来,以更好地保留上下文。
import embed_anything
from embed_anything import EmbeddingModel, TextEmbedConfig, EmbedData
# 加载您的嵌入模型
model = EmbeddingModel.from_pretrained_hf(
model_id="sentence-transformers/all-MiniLM-L12-v2"
)
# 配置延迟分块
config = TextEmbedConfig(
chunk_size=1000, # 最大分块大小
batch_size=8, # 处理批大小
splitting_strategy="sentence", # 首先按句子分割
late_chunking=True, # 启用延迟分块
)
# 使用延迟分块嵌入文件
data: list[EmbedData] = model.embed_file("test_files/attention.pdf", config=config)
# 延迟分块有助于跨句子边界保留上下文
for item in data:
print(f"文本: {item.text}")
print(f"嵌入维度: {len(item.embedding)}")
print("---" * 20)
🧑🚀 快速开始
💚 安装
pip install embed-anything
对于 GPU 和使用特殊模型(如 ColPali)
pip install embed-anything-gpu
🚧❌ 如果在 Windows 上运行时显示 CUDA 错误,请运行以下命令:
os.add_dll_directory("C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.6/bin")
📒 示例 Notebook
| 使用向量数据库适配器进行端到端检索和重排序 |
| ColPali-Onnx |
| 适配器 |
| Qwen3- 嵌入 |
| 性能基准 |
高级配置使用
```python
import embed_anything
from embed_anything import EmbeddingModel, WhichModel, TextEmbed