OA0 ›
代码 ›
MInference — 为长上下文推理优化注意力计算效率
MInference — 为长上下文推理优化注意力计算效率
key · 2026-02-14 02:42:30 · 46 次点击 · 0 条评论
![]()
MInference:面向长上下文大语言模型的百万令牌提示推理加速
| 项目主页 | 论文 | HF 演示 | SCBench | MMInference |
https://github.com/microsoft/MInference/assets/30883354/52613efc-738f-4081-8367-7123c81d6b19
现在,你可以使用长上下文大语言模型(如 LLaMA-3-8B-1M、GLM-4-1M)在单张 A100 上以 10 倍速度 处理 100 万上下文,并且获得 更高的准确率,立即尝试 MInference 1.0!
📰 最新动态
- 🐝 [25/05/02] MMInference 已被 ICML'25 接收。
- 👨💻 [25/04/14] SGLang 和 vLLM 已合并 MInference 稀疏注意力内核。MInference 现已支持优化内核。 只需尝试
pip install sglang。你可以实现高达 1.64× (64K)、2.4× (96K)、2.9× (128K)、5.2× (256K)、8× (512K) 和 15× (1M) 的加速。值得注意的是,SGLang 也将其适配到了 FlashAttention-3。特别感谢 @zhyncs 和 @yinfan98 的贡献! - 👾 [25/04/23] 我们很高兴地宣布发布我们的多模态工作 MMInference,它使用 模态感知排列稀疏注意力 来加速长上下文视觉语言模型。我们将在 ICLR'25 的 Microsoft 展台 和 FW-Wild 上展示 MMInference。新加坡见!
- 🤗 [25/01/27] MInference 已集成到 Qwen2.5-1M 及其在线服务中。详情请参阅 论文 和 vLLM 实现。
- 🪸 [25/01/23] SCBench 已被 ICLR'25 接收。
更多动态
- 🍩 [24/12/13] 我们很高兴地宣布发布我们以 KV 缓存为中心的分析工作 SCBench,它从 KV 缓存的角度评估长上下文方法。
- 🧤 [24/09/26] MInference 已被 NeurIPS'24 接收为 亮点论文。温哥华见!
- 👘 [24/09/16] 我们很高兴地宣布发布我们的 KV 缓存卸载工作 RetrievalAttention,它通过向量检索加速长上下文大语言模型推理。
- 🥤 [24/07/24] MInference 现已支持 meta-llama/Meta-Llama-3.1-8B-Instruct。
- 🪗 [24/07/07] 感谢 @AK 的赞助。你现在可以在 HF 演示 中使用 ZeroGPU 在线体验 MInference。
- 📃 [24/07/03] 由于 arXiv 的问题,PDF 目前无法在该平台获取。你可以通过此 链接 找到论文。
- 🧩 [24/07/03] 我们将在 ICML'24 的 Microsoft 展台 和 ES-FoMo 上展示 MInference 1.0。维也纳见!
一句话总结
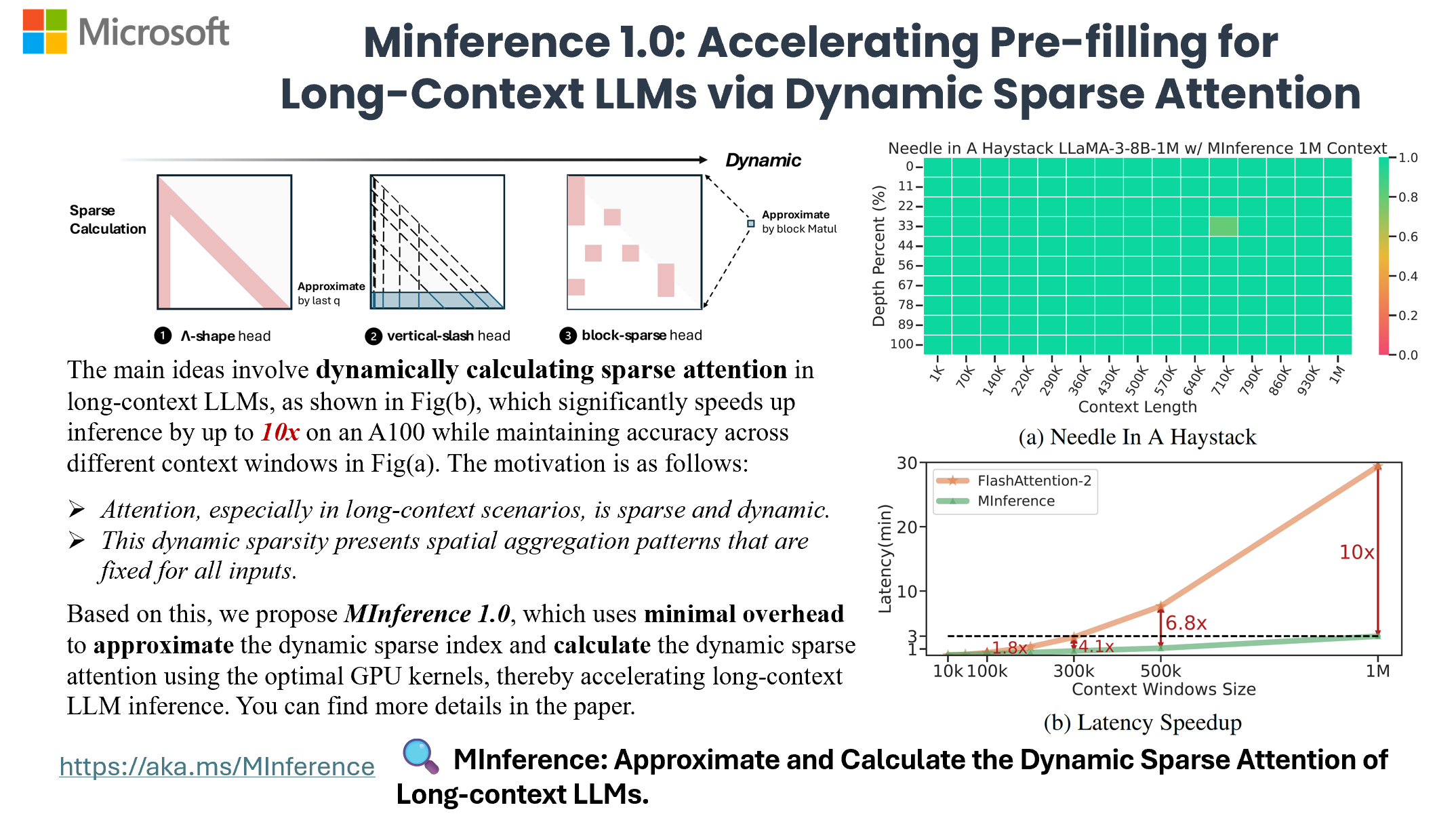
MInference 1.0 利用了大语言模型注意力机制中存在的、具有一定静态模式的动态稀疏特性,来加速长上下文大语言模型的预填充阶段。它首先离线确定每个注意力头所属的稀疏模式,然后在线近似稀疏索引,并使用最优的自定义内核动态计算注意力。这种方法在保持准确性的同时,在 A100 上实现了高达 10 倍的预填充加速。
- MInference 1.0: 通过动态稀疏注意力加速长上下文大语言模型的预填充 (NeurIPS'24 亮点论文, ES-FoMo @ ICML'24)
Huiqiang Jiang†, Yucheng Li†, Chengruidong Zhang†, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang and Lili Qiu
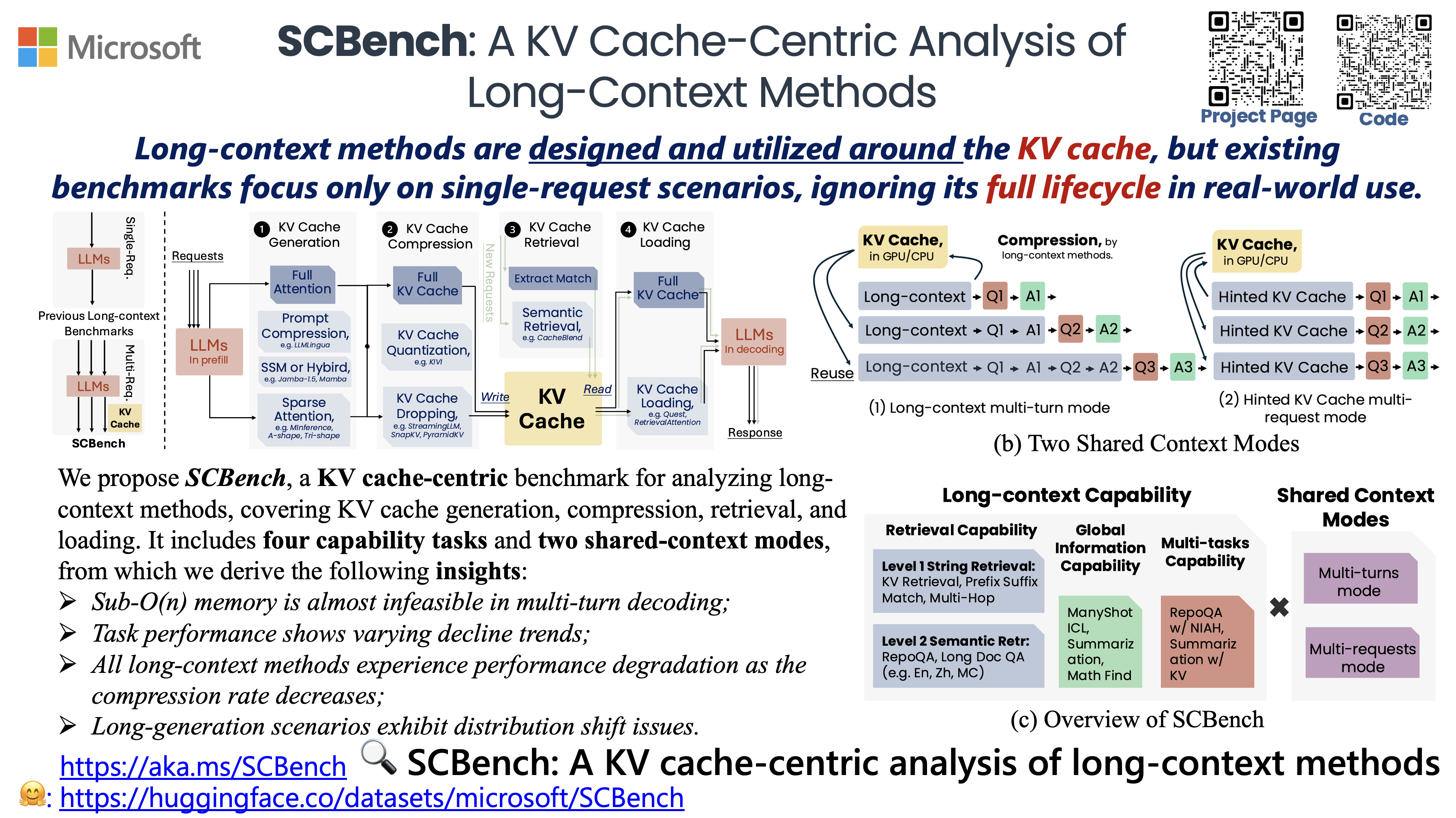
SCBench 从 KV 缓存为中心 的视角,在完整的 KV 缓存生命周期(例如,KV 缓存生成、压缩、检索和加载)中分析长上下文方法。它在两种共享上下文模式下评估了 12 个任务,涵盖了四类长上下文能力:字符串检索、语义检索、全局信息和多任务场景。
- SCBench: 长上下文方法的 KV 缓存中心化分析 (ICLR'25, ENLSP @ NeurIPS'24)
Yucheng Li, Huiqiang Jiang, Qianhui Wu, Xufang Luo, Surin Ahn, Chengruidong Zhang, Amir H. Abdi, Dongsheng Li, Jianfeng Gao, Yuqing Yang and Lili Qiu
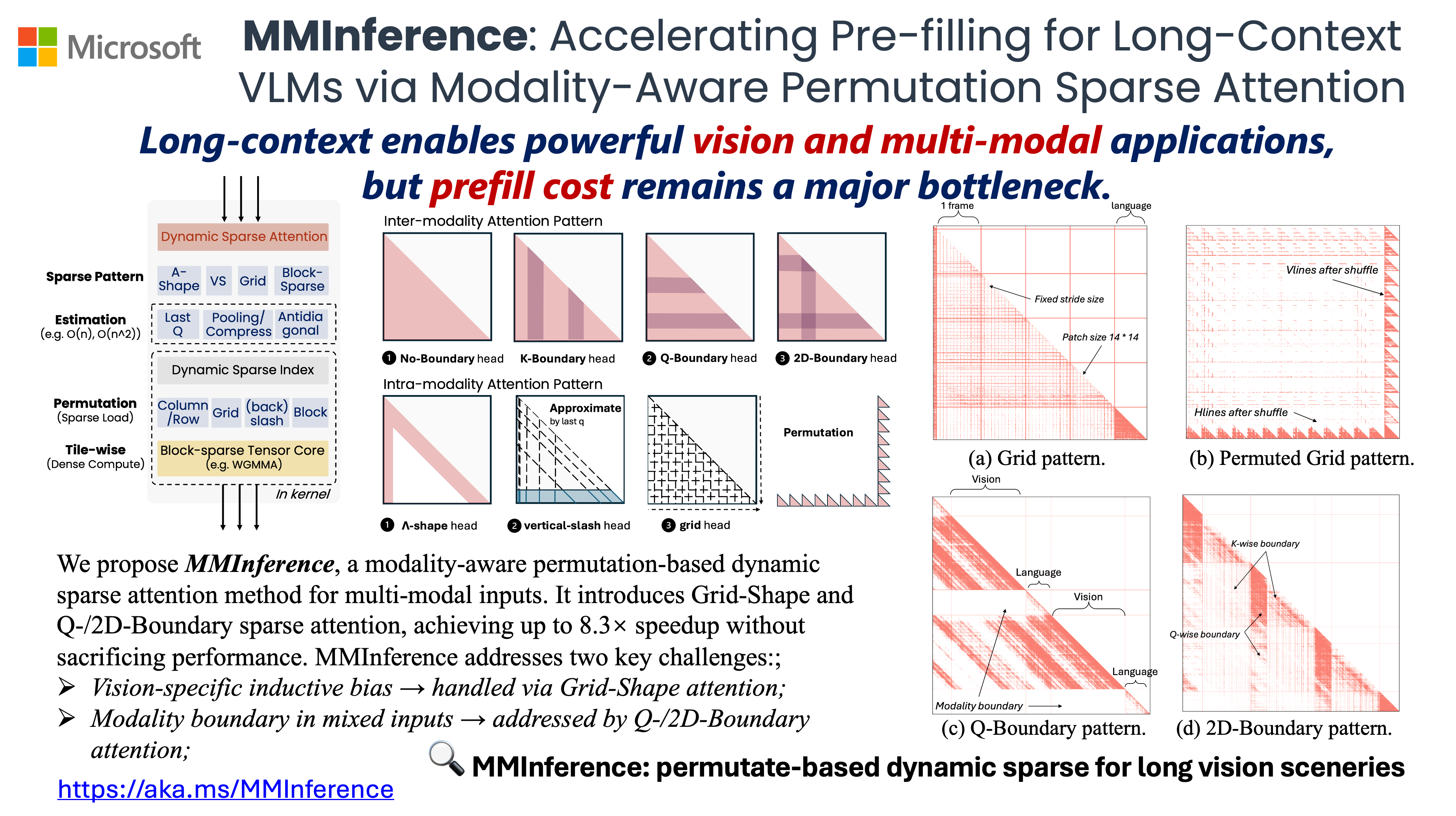
MMInference 使用 模态感知排列稀疏注意力 来加速长上下文视觉语言模型在预填充阶段的推理。具体来说,我们实现了三种不同的基于排列的稀疏注意力机制,结合 FlashAttention、FlashDecoding 和 PIT,以解决视觉输入中的网格模式以及多模态场景中的模态边界问题。
- MMInference: 通过模态感知排列稀疏注意力加速长上下文视觉语言模型的预填充 (ICML'25, FM-Wild @ ICLR'25)
Yucheng Li, Huiqiang Jiang, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Amir H. Abdi, Dongsheng Li, Jianfeng Gao, Yuqing Yang and Lili Qiu
🎥 概览
🎯 快速开始
环境要求
- Torch
- FlashAttention-2 (可选)
- Triton
- Transformers >= 4.46.0
要开始使用 MInference,只需使用 pip 安装:
pip install minference
支持的高效方法
你可以通过运行以下代码获取支持的完整高效方法列表:
from minference import MInferenceConfig
supported_attn_types = MInferenceConfig.get_available_attn_types()
supported_kv_types = MInferenceConfig.get_available_kv_types()
目前,我们支持以下长上下文方法:
- [① KV 缓存生成]: MInference, xAttention, FlexPrefill, A-shape, Tri-shape, MInference w/ static, Dilated, Strided
- [② KV 缓存压缩]: StreamingLLM, SnapKV, PyramidKV, KIVI
- [③ KV 缓存检索]: CacheBlend
- [④ KV 缓存加载]: Quest, RetrievalAttention
关于 KV 缓存生命周期的更多细节,请参考 SCBench。请注意,某些模式由 vLLM 支持,而所有模式均由 HF 支持。
支持的模型
通用的 MInference 支持任何解码式大语言模型,包括 LLaMA 风格模型和 Phi 模型。
我们已经适配了市场上几乎所有开源的长上下文大语言模型。
如果你的模型不在支持列表中,欢迎在 issues 中告知我们,或者你可以按照 指南 手动生成稀疏头配置。
你可以通过运行以下代码获取支持的完整大语言模型列表:
from minference import get_support_models
get_support_models()
目前,我们支持以下大语言模型:
- Qwen2.5: Qwen/Qwen2.5-7B-Instruct, Qwen/Qwen2.5-32B-Instruct, Qwen/Qwen2.5-72B-Instruct, Qwen/Qwen2.5-7B-Instruct-1M, Qwen/Qwen2.5-14B-Instruct-1M
- LLaMA-3.1: meta-llama/Meta-Llama-3.1-8B-Instruct, meta-llama/Meta-Llama-3.1-70B-Instruct
- LLaMA-3: gradientai/Llama-3-8B-Instruct-262k, gradientai/Llama-3-8B-Instruct-Gradient-1048k, gradientai/Llama-3-8B-Instruct-Gradient-4194k, gradientai/Llama-3-70B-Instruct-Gradient-262k, gradientai/Llama-3-70B-Instruct-Gradient-1048k
- GLM-4: THUDM/glm-4-9b-chat-1m
- Yi: 01-ai/Yi-9B-200K
- Phi-3: microsoft/Phi-3-mini-128k-instruct
- Qwen2: Qwen/Qwen2-7B-Instruct
如何使用 MInference
[!TIP]
为了受益于快速内核实现,我们建议安装 SGLang 或 vLLM。
对于 sglang
bash uv pip install "sglang[all]>=0.4.6.post4"对于 vllm
bash uv pip install "vllm>=0.9.0" uv pip install git+https://github.com/vllm-project/flash-attention
对于 HF,
from transformers import pipeline
+from minference import MInference
pipe = pipeline("text-generation", model=model_name, torch_dtype="auto", device_map="auto")
# 应用 MInference 补丁,
# 如果使用本地路径,请在初始化 MInference 时使用 HF 上的 model_name。
+minference_patch = MInference("minference", model_name)
+pipe.model = minference_patch(pipe.model)
pipe(prompt, max_length=10)
# 使用稀疏 KV 方法,例如 snapkv, quest, retr_attn, kivi
+minference_patch = MInference(attn_type="minference", model_name=model_name, kv_type="quest")
+pipe.model = minference_patch(pipe.model)
pipe(prompt, max_length=10)
对于 vLLM,
目前,请使用 vllm>=0.4.1
from vllm import LLM, SamplingParams
+ from minference import MInference
llm = LLM(model_name, enforce_eager=True, max_model_len=128_000, enable_chunked_prefill=False)
# 应用 MInference 补丁,
# 如果使用本地路径,请在初始化 MInference 时使用 HF 上的 model_name。
+minference_patch = MInference("vllm", model_name)
+llm = minference_patch(llm)
outputs = llm.generate(prompts, sampling_params)
对于使用 TP 的 vLLM,
- 将
minference_patch_vllm_tp和minference_patch_vllm_executor从minference/patch.py复制到vllm/worker/worker.py中Worker类的末尾。确保正确缩进minference_patch_vllm_tp。 - 调用 VLLM 时,确保设置
enable_chunked_prefill=False。 - 参考脚本:https://github.com/microsoft/MInference/blob/main/experiments/benchmarks/run_e2e_vllm_tp.sh
from vllm import LLM, SamplingParams
+ from minference import MInference
llm = LLM(model_name, enforce_eager=True, max_model_len=128_000, enable_chunked_prefill=False, tensor_parallel_size=2)
# 应用 MInference 补丁,
# 如果使用本地路径,请在初始化 MInference 时使用 HF 上的 model_name。
+minference_patch = MInference("vllm", model_name)
+llm = minference_patch(llm)
outputs = llm.generate(prompts, sampling_params)
仅使用内核,
from minference import vertical_slash_sparse_attention, block_sparse_attention, streaming_forward
attn_output = vertical_slash_sparse_attention(q, k, v, vertical_topk, slash)
attn_output = block_sparse_attention(q, k, v, topk)
attn_output = streaming_forward(q, k, v, init_num, local_window_num)
对于本地 Gradio 演示

git clone https://huggingface.co/spaces/microsoft/MInference
cd MInference
pip install -r requirments.txt
pip install flash_attn
python app.py
更多细节,请参考我们的