OA0 ›
代码 ›
Liger Kernel — 面向大模型训练的高性能 Triton 内核集合
Liger Kernel — 面向大模型训练的高性能 Triton 内核集合
hundred · 2026-02-14 07:59:40 · 47 次点击 · 0 条评论Liger Kernel:用于 LLM 训练的高效 Triton 内核
| 稳定版 | 每日构建版 | Discord | ||
|---|---|---|---|---|
|
|

|
|

|
|
![]()
安装 | 快速开始 | 示例 | 高级 API | 低级 API | 引用我们的工作
最新动态 🔥
- [2025/12/19] 我们在 https://discord.gg/X4MaxPgA 宣布了 Liger Kernel Discord 频道;我们将在 2026 年 1 月中旬举办 Liger Kernel x Triton 中国见面会。 - [2025/03/06] 我们发布了关于 TorchTune × Liger 的联合博客文章 - [峰值性能,最小化内存:使用 torch.compile 和 Liger Kernel 优化 torchtune 的性能](https://pytorch.org/blog/peak-performance-minimized-memory/)。 - [2024/12/11] 我们发布了 [v0.5.0](https://github.com/linkedin/Liger-Kernel/releases/tag/v0.5.0):训练后损失(DPO、ORPO、CPO 等)内存效率提升 80%! - [2024/12/5] 我们发布了 LinkedIn 工程博客 - [Liger-Kernel:为高效 LLM 训练赋能开源 Triton 内核生态系统](https://www.linkedin.com/blog/engineering/open-source/liger-kernel-open-source-ecosystem-for-efficient-llm-training)。 - [2024/11/6] 我们发布了 [v0.4.0](https://github.com/linkedin/Liger-Kernel/releases/tag/v0.4.0):完整的 AMD 支持、技术报告、Modal CI、Llama-3.2-Vision! - [2024/10/21] 我们在 Arxiv 上发布了 Liger Kernel 的技术报告:https://arxiv.org/pdf/2410.10989。 - [2024/9/6] 我们发布了 v0.2.1 ([X 推文](https://x.com/liger_kernel/status/1832168197002510649))。两周内获得 2500+ Stars,10+ 新贡献者,50+ PRs,50k 下载量! - [2024/8/31] CUDA MODE 演讲,[Liger-Kernel:用于 LLM 训练的真实世界 Triton 内核](https://youtu.be/gWble4FreV4?si=dxPeIchhkJ36Mbns),[幻灯片](https://github.com/cuda-mode/lectures?tab=readme-ov-file#lecture-28-liger-kernel)。 - [2024/8/23] 正式发布:查看我们的 [X 推文](https://x.com/hsu_byron/status/1827072737673982056)。Liger Kernel 是一个专门为 LLM 训练设计的 Triton 内核集合。它能有效提升多 GPU 训练吞吐量达 20%,并减少 60% 的内存使用。我们实现了 与 Hugging Face 兼容 的 RMSNorm、RoPE、SwiGLU、CrossEntropy、FusedLinearCrossEntropy 等,更多功能即将推出。该内核可与 Flash Attention、PyTorch FSDP 和 Microsoft DeepSpeed 开箱即用。我们欢迎社区贡献,以汇集用于 LLM 训练的最佳内核。
我们还添加了优化的训练后内核,为对齐和蒸馏任务提供 高达 80% 的内存节省。我们支持 DPO、CPO、ORPO、SimPO、KTO、JSD 等多种损失函数。查看 我们如何优化内存。
你可以访问文档站点获取额外的安装说明、使用示例和 API 参考:https://linkedin.github.io/Liger-Kernel/
你可以查看 Liger Kernel 技术报告:https://openreview.net/forum?id=36SjAIT42G
使用 Liger Kernel 为你的模型加速

只需一行代码,Liger Kernel 就能将吞吐量提升 20% 以上,并将内存使用减少 60%,从而实现更长的上下文长度、更大的批处理规模和更大的词汇表。
| 速度提升 | 内存减少 |
|---|---|
 |
 |
注意:
- 基准测试条件:LLaMA 3-8B,批大小 = 8,数据类型 =bf16,优化器 = AdamW,梯度检查点 = True,分布式策略 = 8 个 A100 上的 FSDP1。
- Hugging Face 模型在 4K 上下文长度时开始 OOM,而 Hugging Face + Liger Kernel 可以扩展到 16K。
使用 Liger Kernel 优化训练后任务
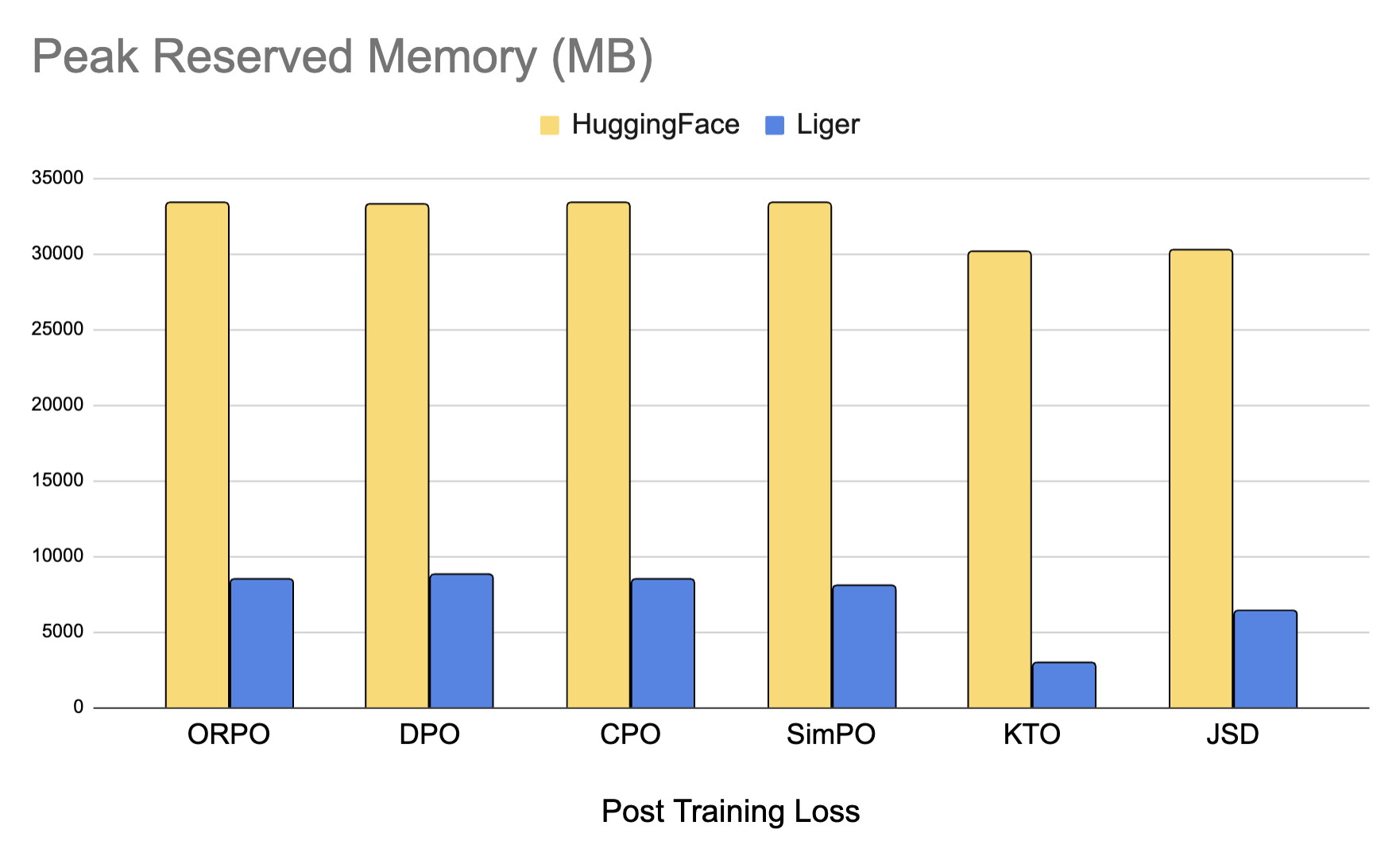
我们提供了优化的训练后内核,如 DPO、ORPO、SimPO 等,可减少高达 80% 的内存使用。你可以轻松地将它们用作 Python 模块。
from liger_kernel.chunked_loss import LigerFusedLinearORPOLoss
orpo_loss = LigerFusedLinearORPOLoss()
y = orpo_loss(lm_head.weight, x, target)
示例
| 用例 | 描述 |
|---|---|
| Hugging Face Trainer | 在 Alpaca 数据集上使用 4 个 A100 和 FSDP,训练 LLaMA 3-8B 速度提升约 20%,内存减少超过 40% |
| Lightning Trainer | 在 MMLU 数据集上使用 8 个 A100 和 DeepSpeed ZeRO3,LLaMA3-8B 吞吐量提升 15%,内存使用减少 40% |
| Medusa 多头 LLM(重训练阶段) | 使用 5 个 LM 头,内存使用减少 80%,吞吐量提升 40%,使用 8 个 A100 和 FSDP |
| 视觉语言模型 SFT | 在图像-文本数据上使用 4 个 A100 和 FSDP 微调 Qwen2-VL |
| Liger ORPO Trainer | 使用 Liger ORPO Trainer 和 FSDP 对齐 Llama 3.2,内存减少 50% |
主要特性
- 易于使用: 只需一行代码即可为你的 Hugging Face 模型打补丁,或使用我们的 Liger Kernel 模块组合你自己的模型。
- 时间和内存高效: 秉承与 Flash-Attn 相同的精神,但针对 RMSNorm、RoPE、SwiGLU 和 CrossEntropy 等层!通过内核融合、原地替换和分块技术,将多 GPU 训练吞吐量提升 20%,内存使用减少 60%。
- 精确: 计算是精确的——没有近似!前向和后向传播均经过严格的单元测试,并与未使用 Liger Kernel 的训练运行进行收敛性测试,以确保准确性。
- 轻量级: Liger Kernel 依赖项极少,仅需 Torch 和 Triton——无需额外库!告别依赖项困扰!
- 支持多 GPU: 兼容多 GPU 设置(PyTorch FSDP、DeepSpeed、DDP 等)。
- 训练器框架集成: Axolotl、LLaMa-Factory、SFTTrainer、Hugging Face Trainer、SWIFT、oumi
安装
依赖项
CUDA
torch >= 2.1.2triton >= 2.3.0
ROCm
torch >= 2.5.0根据 PyTorch 官方网页的说明安装。triton >= 3.0.0从 pypi 安装。(例如pip install triton==3.0.0)
pip install -e .[dev]
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/rocm6.3/
可选依赖项
transformers >= 4.x:如果你计划使用 transformers 模型打补丁 API,则需要。你正在使用的具体模型将决定 transformers 的最低版本。
注意:
我们的内核继承了 Triton 提供的完整硬件兼容性。
安装稳定版:
$ pip install liger-kernel
安装每日构建版:
$ pip install liger-kernel-nightly
从源码安装:
git clone https://github.com/linkedin/Liger-Kernel.git
cd Liger-Kernel
# 安装默认依赖项
# Setup.py 会检测你使用的是 AMD 还是 NVIDIA
pip install -e .
# 安装开发依赖项
pip install -e ".[dev]"
# 注意 -> 仅适用于 AMD 用户
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/rocm6.3/
快速开始
根据所需的定制化程度,有几种应用 Liger 内核的方法。
1. 使用 AutoLigerKernelForCausalLM
使用 AutoLigerKernelForCausalLM 是最简单的方法,因为你不需要导入特定于模型的打补丁 API。如果模型类型受支持,建模代码将使用默认设置自动打补丁。
from liger_kernel.transformers import AutoLigerKernelForCausalLM
# 这个 AutoModel 包装类会自动为支持的模型打上优化的 Liger 内核补丁。
model = AutoLigerKernelForCausalLM.from_pretrained("path/to/some/model")
2. 应用特定于模型的打补丁 API
使用打补丁 API,你可以将 Hugging Face 模型替换为优化的 Liger 内核。
import transformers
from liger_kernel.transformers import apply_liger_kernel_to_llama
# 1a. 添加此行会自动为模型打上优化的 Liger 内核补丁
apply_liger_kernel_to_llama()
# 1b. 或者,你可以指定具体应用哪些内核
apply_liger_kernel_to_llama(
rope=True,
swiglu=True,
cross_entropy=True,
fused_linear_cross_entropy=False,
rms_norm=False
)
# 2. 实例化已打补丁的模型
model = transformers.AutoModelForCausalLM("path/to/llama/model")
3. 组合你自己的模型
你可以使用单独的内核来组合你的模型。
from liger_kernel.transformers import LigerFusedLinearCrossEntropyLoss
import torch.nn as nn
import torch
model = nn.Linear(128, 256).cuda()
# 将线性层和交叉熵层融合在一起,并执行分块计算以减少内存
loss_fn = LigerFusedLinearCrossEntropyLoss()
input = torch.randn(4, 128, requires_grad=True, device="cuda")
target = torch.randint(256, (4, ), device="cuda")
loss = loss_fn(model.weight, input, target)
loss.backward()
高级 API
AutoModel
| AutoModel 变体 | API |
|---|---|
| AutoModelForCausalLM | liger_kernel.transformers.AutoLigerKernelForCausalLM |
打补丁
| 模型 | API | 支持的操作 |
|---|---|---|
| Llama4 (文本) & (多模态) | liger_kernel.transformers.apply_liger_kernel_to_llama4 |
RMSNorm, LayerNorm, GeGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| LLaMA 2 & 3 | liger_kernel.transformers.apply_liger_kernel_to_llama |
RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| LLaMA 3.2-Vision | `liger_kernel.transformers.apply_lig |