OA0 ›
代码 ›
WhisperX — 更精准的语音识别与时间轴对齐工具
WhisperX — 更精准的语音识别与时间轴对齐工具
kingdom · 2026-02-15 17:29:09 · 46 次点击 · 0 条评论WhisperX
Recall.ai - 会议转录 API
如果您正在寻找用于会议的转录 API,可以考虑使用 Recall.ai 的会议转录 API。该 API 支持 Zoom、Google Meet、Microsoft Teams 等平台。Recall.ai 通过从会议平台提取说话人数据和独立的音频流来实现说话人日志,这意味着可以获得 100% 准确的说话人日志以及真实的说话人姓名。



![]()

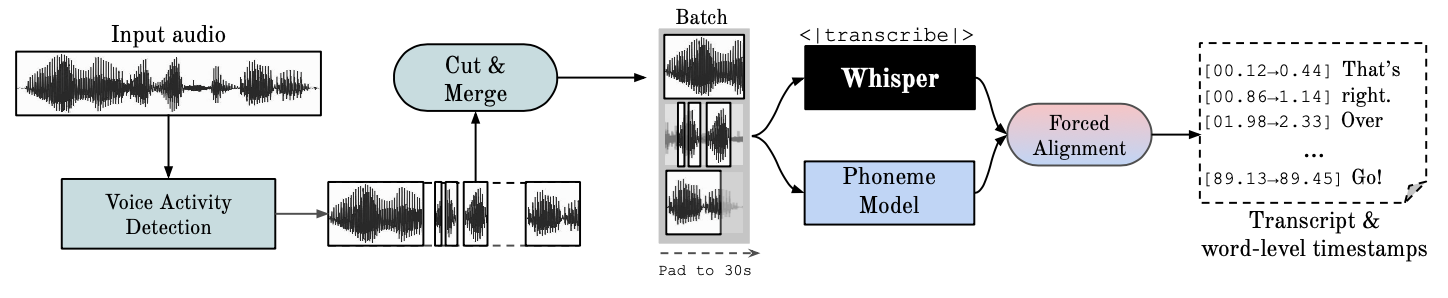
本仓库提供快速的自动语音识别(使用 large-v2 模型可达 70 倍实时速度),并带有词级时间戳和说话人日志功能。
- ⚡️ 使用 whisper large-v2 进行批量推理,实现 70 倍实时转录
- 🪶 使用 faster-whisper 后端,在 beam_size=5 时运行 large-v2 模型所需 GPU 内存 <8GB
- 🎯 使用 wav2vec2 对齐实现准确的词级时间戳
- 👯♂️ 使用 pyannote-audio 的说话人日志功能实现多说话人 ASR(说话人 ID 标签)
- 🗣️ VAD 预处理,减少幻觉,并在不降低 WER 的情况下实现批量处理
Whisper 是 由 OpenAI 开发 的 ASR 模型,在大量多样化的音频数据上训练而成。虽然它能产生高度准确的转录文本,但其对应的时间戳是在话语级别,而非词级,并且可能存在几秒钟的误差。OpenAI 的 whisper 本身不支持批处理。
基于音素的 ASR 是一套经过微调的模型,用于识别区分单词的最小语音单位,例如 "tap" 中的 p 音。一个流行的示例模型是 wav2vec2.0。
强制对齐 是指将正字法转录与音频记录对齐,以自动生成音素级别分割的过程。
语音活动检测 (VAD) 是检测人类语音存在与否的过程。
说话人日志 是根据每个说话人的身份,将包含人类语音的音频流划分为同质片段的过程。
最新动态 🚨
- 在 Ego4d 转录挑战赛 中获得第一名 🏆
- WhisperX 被 INTERSPEECH 2023 接收
- v3 版本:使用 nltk sent_tokenize 实现按句子划分转录片段,以获得更好的字幕效果和说话人日志
- v3 版本发布,开源了 70 倍加速!使用基于 faster-whisper 后端的批处理 whisper
- v2 版本发布,代码清理,导入 whisper 库,VAD 过滤现在默认开启(与论文中一致)
- 论文发布🎓👨🏫!请参阅我们的 ArxiV 预印本 了解 WhisperX 的基准测试和详细信息。我们还介绍了更高效的批处理推理,使得 large-v2 模型具有 *60-70 倍实时速度。
安装 ⚙️
0. CUDA 安装
要在 GPU 加速下使用 WhisperX,请在安装 WhisperX 之前先安装 CUDA 12.8 工具包。如果仅使用 CPU,请跳过此步骤。
- Linux 用户,请按照此指南安装 CUDA 12.8 工具包:
Linux 的 CUDA 安装指南。 - Windows 用户,请下载并安装 CUDA 12.8 工具包:
CUDA 下载。
1. 简单安装(推荐)
安装 WhisperX 最简单的方法是通过 PyPi:
pip install whisperx
或者,如果使用 uvx:
uvx whisperx
2. 高级安装选项
这些安装方法适用于开发者或有特定需求的用户。如果不确定,请使用上面的简单安装方法。
选项 A:从 GitHub 安装
直接从 GitHub 仓库安装:
uvx git+https://github.com/m-bain/whisperX.git
选项 B:开发者安装
如果想修改代码或为项目做贡献:
git clone https://github.com/m-bain/whisperX.git
cd whisperX
uv sync --all-extras --dev
注意:开发版本可能包含实验性功能和错误。生产环境请使用稳定的 PyPI 版本。
您可能还需要安装 ffmpeg、rust 等。请按照 OpenAI 的说明操作:https://github.com/openai/whisper#setup。
说话人日志
要启用说话人日志,请在 --hf_token 参数后包含您的 Hugging Face 访问令牌(读取权限),您可以从这里生成,并接受 speaker-diarization-community-1 模型的用户协议。
用法 💬(命令行)
英语
在示例片段上运行 whisper(使用默认参数,whisper small 模型)。添加 --highlight_words True 以在 .srt 文件中可视化单词时间。
whisperx path/to/audio.wav
使用 WhisperX 与 wav2vec2.0 large 模型强制对齐的结果:
https://user-images.githubusercontent.com/36994049/208253969-7e35fe2a-7541-434a-ae91-8e919540555d.mp4
与原始开箱即用的 whisper 对比,后者的许多转录文本不同步:
https://user-images.githubusercontent.com/36994049/207743923-b4f0d537-29ae-4be2-b404-bb941db73652.mov
为了提高时间戳精度(以更高的 GPU 内存为代价),可以使用更大的模型(更大的对齐模型帮助不大,参见论文),例如:
whisperx path/to/audio.wav --model large-v2 --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --batch_size 4
为转录文本标记说话人 ID(如果已知说话人数量,请设置,例如 --min_speakers 2 --max_speakers 2):
whisperx path/to/audio.wav --model large-v2 --diarize --highlight_words True
在 CPU 上运行(以及在 Mac OS X 上运行):
whisperx path/to/audio.wav --compute_type int8 --device cpu
其他语言
音素 ASR 对齐模型是_语言特定_的,对于已测试的语言,这些模型会自动从 torchaudio 管道或 huggingface 中选择。
只需传入 --language 代码,并使用 whisper --model large。
目前通过 torchaudio 管道为 {en, fr, de, es, it} 提供了默认模型,并通过 Hugging Face 为许多其他语言提供了模型。请在 alignment.py 的 DEFAULT_ALIGN_MODELS_HF 下查找当前支持的语言列表。如果检测到的语言不在此列表中,您需要从 huggingface 模型中心 找到一个基于音素的 ASR 模型并在您的数据上进行测试。
例如:德语
whisperx --model large-v2 --language de path/to/audio.wav
https://user-images.githubusercontent.com/36994049/208298811-e36002ba-3698-4731-97d4-0aebd07e0eb3.mov
查看其他语言的更多示例请点击这里。
Python 用法 🐍
import whisperx
import gc
from whisperx.diarize import DiarizationPipeline
device = "cuda"
audio_file = "audio.mp3"
batch_size = 16 # 如果 GPU 内存不足,请减小此值
compute_type = "float16" # 如果 GPU 内存不足,可改为 "int8"(可能降低精度)
# 1. 使用原始 whisper 进行转录(批处理)
model = whisperx.load_model("large-v2", device, compute_type=compute_type)
# 将模型保存到本地路径(可选)
# model_dir = "/path/"
# model = whisperx.load_model("large-v2", device, compute_type=compute_type, download_root=model_dir)
audio = whisperx.load_audio(audio_file)
result = model.transcribe(audio, batch_size=batch_size)
print(result["segments"]) # 对齐前
# 如果 GPU 资源紧张,删除模型
# import gc; import torch; gc.collect(); torch.cuda.empty_cache(); del model
# 2. 对齐 whisper 输出
model_a, metadata = whisperx.load_align_model(language_code=result["language"], device=device)
result = whisperx.align(result["segments"], model_a, metadata, audio, device, return_char_alignments=False)
print(result["segments"]) # 对齐后
# 如果 GPU 资源紧张,删除模型
# import gc; import torch; gc.collect(); torch.cuda.empty_cache(); del model_a
# 3. 分配说话人标签
diarize_model = DiarizationPipeline(token=YOUR_HF_TOKEN, device=device)
# 如果已知说话人数量范围,可添加 min/max 参数
diarize_segments = diarize_model(audio)
# diarize_model(audio, min_speakers=min_speakers, max_speakers=max_speakers)
result = whisperx.assign_word_speakers(diarize_segments, result)
print(diarize_segments)
print(result["segments"]) # 片段现在已分配说话人 ID
演示 🚀



如果您没有自己的 GPU,可以使用上面的链接尝试 WhisperX。
技术细节 👷♂️
有关批处理和对齐的具体细节、VAD 的效果以及所选对齐模型的详细信息,请参阅预印本论文。
要减少 GPU 内存需求,请尝试以下任何方法(2. 和 3. 可能影响质量):
- 减小批处理大小,例如
--batch_size 4 - 使用更小的 ASR 模型
--model base - 使用更轻量的计算类型
--compute_type int8
与 OpenAI 的 whisper 的转录差异:
- 不带时间戳的转录。为了实现单次批处理,whisper 推理以
--without_timestamps True执行,这确保了批次中每个样本进行一次前向传递。然而,这可能导致与默认 whisper 输出的差异。 - 基于 VAD 的片段转录,不同于 OpenAI 的缓冲转录。在 WhisperX 论文中,我们展示了这可以降低 WER,并实现准确的批处理推理。
--condition_on_prev_text默认设置为False(减少幻觉)。
限制 ⚠️
- 转录词中不包含对齐模型字典中的字符,例如 "2014." 或 "£13.60",无法对齐,因此没有时间戳。
- Whisper 和 WhisperX 都不能很好地处理重叠语音。
- 说话人日志远非完美。
- 需要语言特定的 wav2vec2 模型。
贡献 🧑🏫
如果您是多语言者,为该项目做出贡献的主要方式是,在 huggingface 上找到(或训练自己的)目标语言的音素模型,并在语音上进行测试。如果结果良好,请提交拉取请求和一些展示其成功运行的示例。
发现错误和提交拉取请求也非常受欢迎,以保持该项目持续发展,因为它已经偏离了最初的研究范围。
待办事项 🗓
- [x] 多语言初始化
- [x] 基于语言检测的自动对齐模型选择
- [x] Python 用法
- [x] 集成说话人日志
- [x] 模型刷新,适用于低 GPU 内存资源
- [x] Faster-whisper 后端
- [x] 添加 max-line 等,参见(openai 的 whisper utils.py)
- [x] 句子级别片段(nltk 工具箱)
- [x] 改进对齐逻辑
- [ ] 使用说话人日志和单词高亮更新示例
- [ ] 字幕 .ass 输出 <- 恢复此功能(在 v3 中移除)
- [ ] 添加基准测试代码(用于 spd/WER 和词分割的 TEDLIUM)
- [x] 允许将 silero-vad 作为替代 VAD 选项
- [ ] 改进说话人日志(词级)。比最初想象的要难...
联系/支持 📇
如有疑问,请联系 maxhbain@gmail.com。
![]()
致谢 🙏
这项工作以及我的博士研究得到了 VGG(视觉几何组) 和牛津大学的支持。
当然,这建立在 OpenAI 的 whisper 之上。
借鉴了 PyTorch 强制对齐教程 中的重要对齐代码。
并使用了出色的 pyannote VAD / 说话人日志 https://github.com/pyannote/pyannote-audio
有价值的 VAD 和说话人日志模型来自:
- pyannote-audio — 说话人日志功能由 speaker-diarization-community-1 模型提供支持,由 pyannoteAI 根据 CC-BY-4.0 许可授权。
- [silero-vad](https://github.com/snakers4/silero