OA0 ›
代码 ›
OpenPrompt — 面向提示学习的开源研究框架
OpenPrompt — 面向提示学习的开源研究框架
opt · 2026-02-26 23:20:48 · 48 次点击 · 0 条评论 **一个用于提示学习(Prompt-learning)的开源框架。**
------
**一个用于提示学习(Prompt-learning)的开源框架。**
------
最新动态
- ❗️ 2023年4月:$\color{red}{\normalsize{\textbf{想构建自己的聊天AI吗?}}}$ 我们发布了 UltraChat,使用 OpenPrompt 和 UltraChat 进行监督式指令微调,请参见
./tutorial/9_UltraChat.py。 - 2022年8月:感谢贡献者 zhiyongLiu1114,OpenPrompt 现在支持 PaddlePaddle 框架下的 ERNIE 1.0。
- 2022年7月:OpenPrompt 现已支持 OPT 模型。
- 2022年6月:OpenPrompt 荣获 ACL 2022 最佳演示论文奖。
- 2022年3月:我们新增了一个教程作为对 issue 124 的回应,该教程使用自定义的 tokenizer_wrapper 来执行 OpenPrompt 默认配置不支持的任务(例如,Bert tokenizer + T5 模型)。
- 2022年2月:欢迎查看我们的姊妹项目 OpenDelta!
- 2021年12月:
pip install openprompt - 2021年12月:添加了 SuperGLUE 性能 结果。
- 2021年12月:我们通过新增一个 Verbalizer:GenerationVerbalizer 和一个教程:4.1_all_tasks_are_generation.py,支持所有任务的生成范式。
- 2021年11月:我们发布了一篇论文 OpenPrompt: An Open-source Framework for Prompt-learning。
- 2021年11月:PrefixTuning 现已支持 T5 模型。
- 2021年11月:我们进行了自上一版本以来的一些重大更改,引入了灵活的模板语言!部分文档已过时,我们将尽快修复。
概述
提示学习(Prompt-learning) 是使预训练语言模型(PLMs)适应下游 NLP 任务的最新范式,它通过文本模板修改输入文本,并直接使用 PLM 执行预训练任务。本库提供了一个标准、灵活且可扩展的框架来部署提示学习流程。OpenPrompt 支持直接从 huggingface transformers 加载 PLM。未来,我们也将支持其他库实现的 PLM。关于提示学习的更多资源,请查阅我们的论文列表。
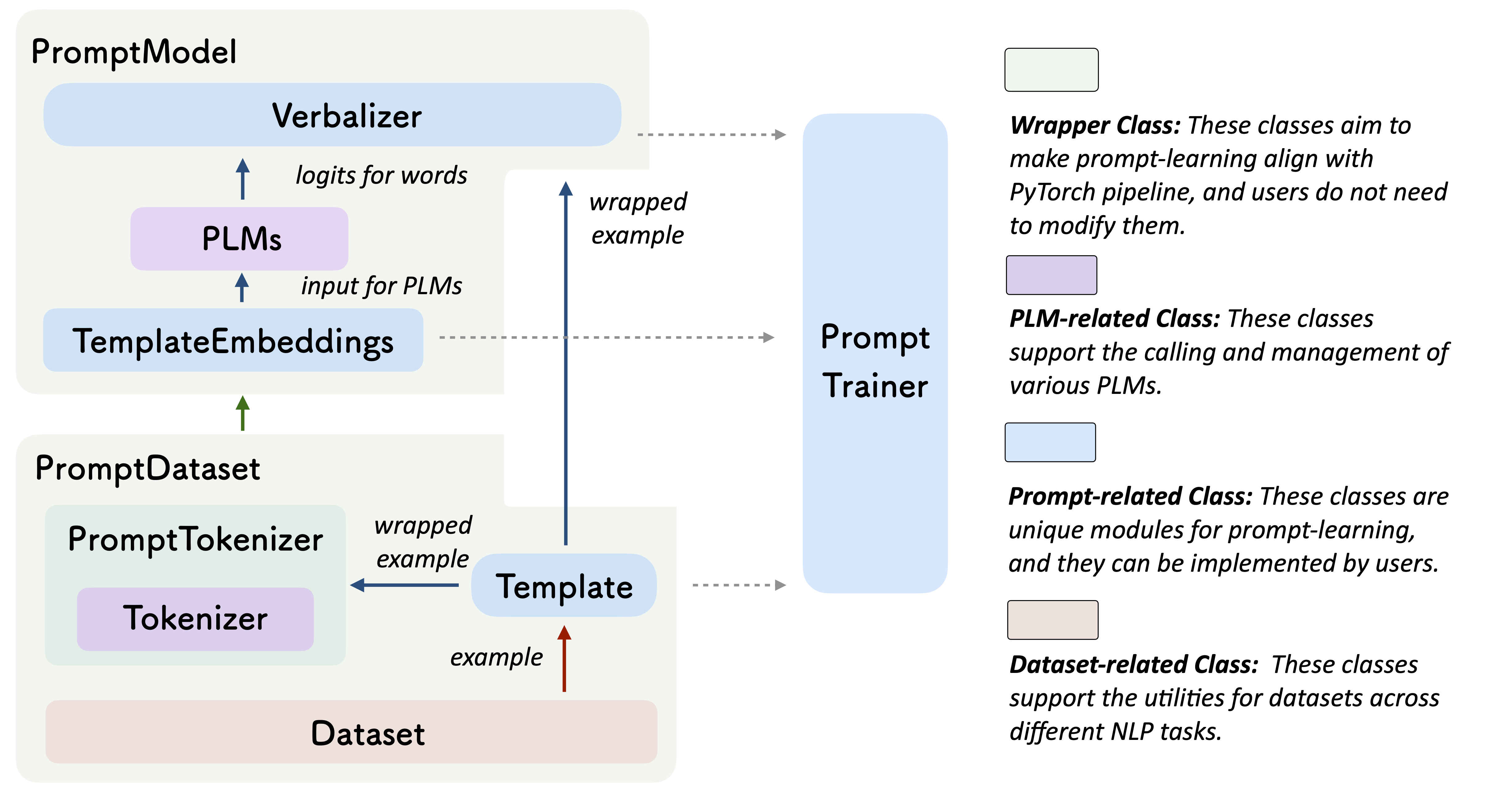
通过 OpenPrompt 你能做什么?

- 使用当前主流提示学习方法的实现。 我们在统一标准下实现了多种提示方法,包括模板构建、标签词映射和优化策略。你可以轻松调用和理解这些方法。
- 设计你自己的提示学习工作。 借助 OpenPrompt 的可扩展性,你可以快速实践你的提示学习想法。
安装
注意:请使用 Python 3.8+ 运行 OpenPrompt
使用 Pip
我们的仓库在 Python 3.8+ 和 PyTorch 1.8.1+ 环境下测试通过,使用 pip 安装 OpenPrompt 如下:
pip install openprompt
如果你想体验最新功能,也可以从源码安装。
使用 Git
从 GitHub 克隆仓库:
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py install
修改代码后,使用以下命令进行开发模式安装:
python setup.py develop
使用 OpenPrompt
基本概念
一个 PromptModel 对象包含一个 PLM、一个(或多个)Template 以及一个(或多个)Verbalizer。其中,Template 类用于使用模板包装原始输入,Verbalizer 类用于在当前词汇表中构建标签与目标词之间的映射。PromptModel 对象实际参与训练和推理过程。
一个简单示例
借助 OpenPrompt 的模块化和灵活性,你可以轻松开发一个提示学习流程。
步骤 1:定义任务
第一步是确定当前的 NLP 任务,思考你的数据是什么样子以及你想从数据中得到什么!也就是说,这一步的本质是确定任务的 classes 和 InputExample。为简单起见,我们以情感分析为例。
from openprompt.data_utils import InputExample
classes = [ # 情感分析中有两个类别,一个代表负面,一个代表正面
"negative",
"positive"
]
dataset = [ # 为简单起见,这里只有两个示例
# text_a 是数据的输入文本,有些数据集的一个示例中可能包含多个输入句子。
InputExample(
guid = 0,
text_a = "Albert Einstein was one of the greatest intellects of his time.",
),
InputExample(
guid = 1,
text_a = "The film was badly made.",
),
]
步骤 2:定义预训练语言模型(PLM)作为主干
选择一个 PLM 来支持你的任务。不同的模型具有不同的属性,我们鼓励你使用 OpenPrompt 探索各种 PLM 的潜力。OpenPrompt 兼容 huggingface 上的模型。
from openprompt.plms import load_plm
plm, tokenizer, model_config, WrapperClass = load_plm("bert", "bert-base-cased")
步骤 3:定义模板
Template 是对原始输入文本的修饰器,也是提示学习中最重要的模块之一。我们在步骤 1 中已经定义了 text_a。
from openprompt.prompts import ManualTemplate
promptTemplate = ManualTemplate(
text = '{"placeholder":"text_a"} It was {"mask"}',
tokenizer = tokenizer,
)
步骤 4:定义标签词映射器
Verbalizer 是提示学习中另一个重要(但非必需)的模块,它将原始标签(我们已将其定义为 classes,还记得吗?)映射到一组标签词。这里是一个示例:我们将 negative 类映射到单词 bad,将 positive 类映射到单词 good、wonderful、great。
from openprompt.prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer(
classes = classes,
label_words = {
"negative": ["bad"],
"positive": ["good", "wonderful", "great"],
},
tokenizer = tokenizer,
)
步骤 5:将它们组合成一个 PromptModel
给定任务,现在我们有了 PLM、Template 和 Verbalizer,我们将它们组合成一个 PromptModel。请注意,尽管这个示例简单地将三个模块组合在一起,但实际上你可以在它们之间定义一些复杂的交互。
from openprompt import PromptForClassification
promptModel = PromptForClassification(
template = promptTemplate,
plm = plm,
verbalizer = promptVerbalizer,
)
步骤 6:定义数据加载器
PromptDataLoader 基本上是 PyTorch Dataloader 的提示学习版本,它还包含一个 Tokenizer、一个 Template 和一个 TokenizerWrapper。
from openprompt import PromptDataLoader
data_loader = PromptDataLoader(
dataset = dataset,
tokenizer = tokenizer,
template = promptTemplate,
tokenizer_wrapper_class=WrapperClass,
)
步骤 7:训练和推理
完成!我们可以像 PyTorch 中的其他流程一样进行训练和推理。
import torch
# 使用预训练的 MLM 和提示进行零样本推理
promptModel.eval()
with torch.no_grad():
for batch in data_loader:
logits = promptModel(batch)
preds = torch.argmax(logits, dim = -1)
print(classes[preds])
# 对于类别 'positive', 'negative',预测结果将是 1, 0
数据集
我们在 dataset/ 文件夹中提供了一系列下载脚本,欢迎使用它们下载基准测试数据集。
性能报告
OpenPrompt 支持太多可能的组合。我们正在尽力尽快测试不同方法的性能。性能结果将持续更新到表格中。我们也鼓励用户为自己的任务寻找最佳超参数,并通过提交 Pull Request 来报告结果。
已知问题
未来主要的改进/增强方向:
- 我们自上一版本进行了一些重大更改,因此部分文档已过时。我们将尽快修复。
引用
如果你在工作中使用了 OpenPrompt,请引用我们的论文。
@article{ding2021openprompt,
title={OpenPrompt: An Open-source Framework for Prompt-learning},
author={Ding, Ning and Hu, Shengding and Zhao, Weilin and Chen, Yulin and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong},
journal={arXiv preprint arXiv:2111.01998},
year={2021}
}
贡献者
我们感谢所有对本项目做出贡献的人,欢迎更多贡献者!