OA0 ›
代码 ›
Mistral.rs — 高性能 Rust 推理库,适合本地部署大模型
Mistral.rs — 高性能 Rust 推理库,适合本地部署大模型
joyful · 2026-03-29 11:00:21 · 65 次点击 · 0 条评论
快速、灵活的大语言模型推理引擎。
| 文档 | Rust SDK | Python SDK | Discord |

为什么选择 mistral.rs?
- 零配置运行任何 HuggingFace 模型:只需
mistralrs run -m user/model。自动检测架构、量化格式和聊天模板。 - 真正的多模态支持:视觉、音频、语音生成、图像生成、嵌入模型。
- 非模型注册中心:直接使用 HuggingFace 模型,无需转换或上传到其他服务。
- 完整的量化控制:选择你想要的精确量化方式,或使用
mistralrs quantize制作自己的 UQFF 量化。 - 内置 Web UI:
mistralrs serve --ui立即提供一个 Web 界面。 - 硬件感知:
mistralrs tune为你的系统进行基准测试并选择最优的量化方式和设备映射。 - 灵活的 SDK:提供 Python 包和 Rust crate,用于构建你的项目。
快速开始
安装
Linux/macOS:
curl --proto '=https' --tlsv1.2 -sSf https://raw.githubusercontent.com/EricLBuehler/mistral.rs/master/install.sh | sh
Windows (PowerShell):
irm https://raw.githubusercontent.com/EricLBuehler/mistral.rs/master/install.ps1 | iex
运行你的第一个模型
# 交互式聊天
mistralrs run -m Qwen/Qwen3-4B
# 或者启动一个带 Web UI 的服务器
mistralrs serve --ui -m google/gemma-3-4b-it
然后访问 http://localhost:1234/ui 即可使用网页聊天界面。
mistralrs 命令行工具
CLI 设计为零配置:只需指向一个模型即可运行。
- 自动检测:自动检测模型架构、量化格式和聊天模板
- 一体化:单个二进制文件支持聊天、服务器、基准测试和 Web UI (
run,serve,bench) - 硬件调优:运行
mistralrs tune自动进行基准测试并为你的硬件配置最优设置 - 格式无关:无缝支持 Hugging Face 模型、GGUF 文件和 UQFF 量化
# 为你的硬件自动调优并生成配置文件
mistralrs tune -m Qwen/Qwen3-4B --emit-config config.toml
# 使用生成的配置运行
mistralrs from-config -f config.toml
# 诊断系统问题(CUDA、Metal、HuggingFace 连接性)
mistralrs doctor
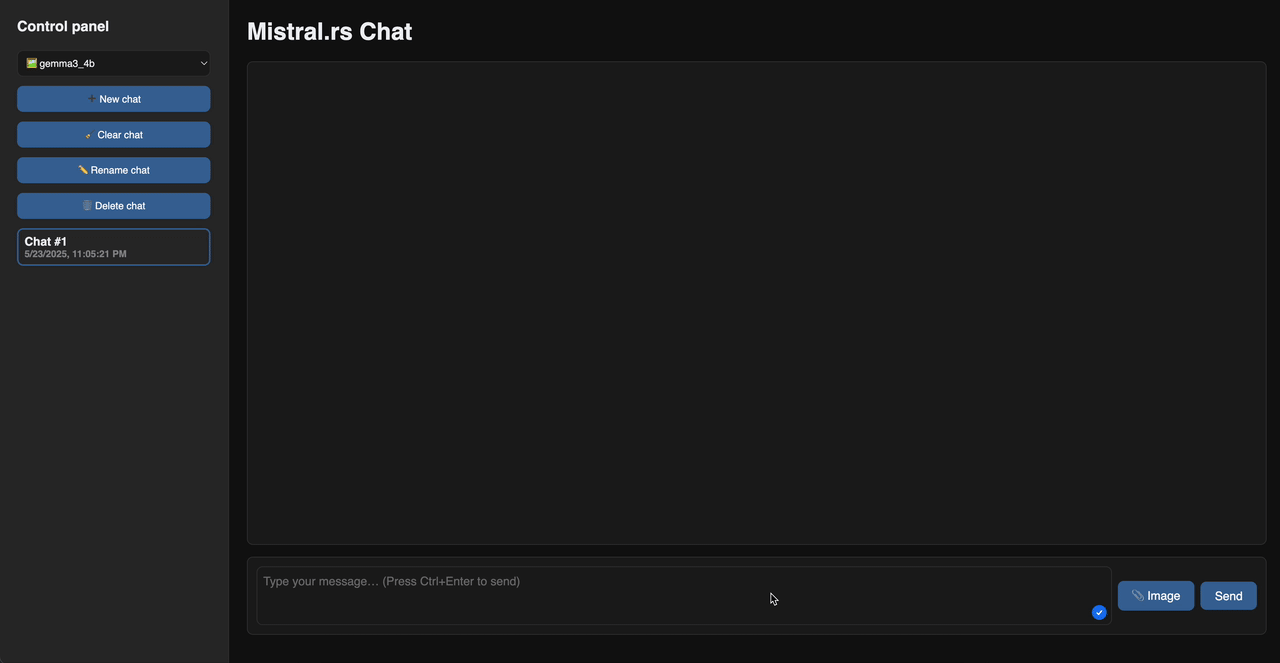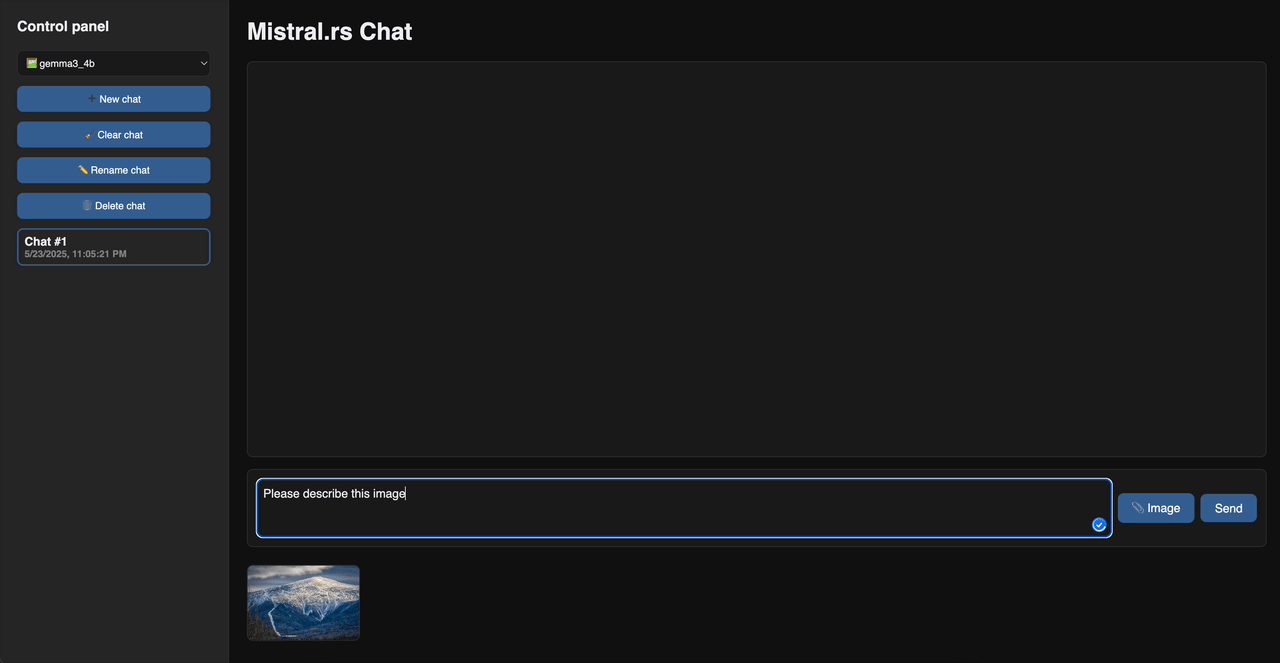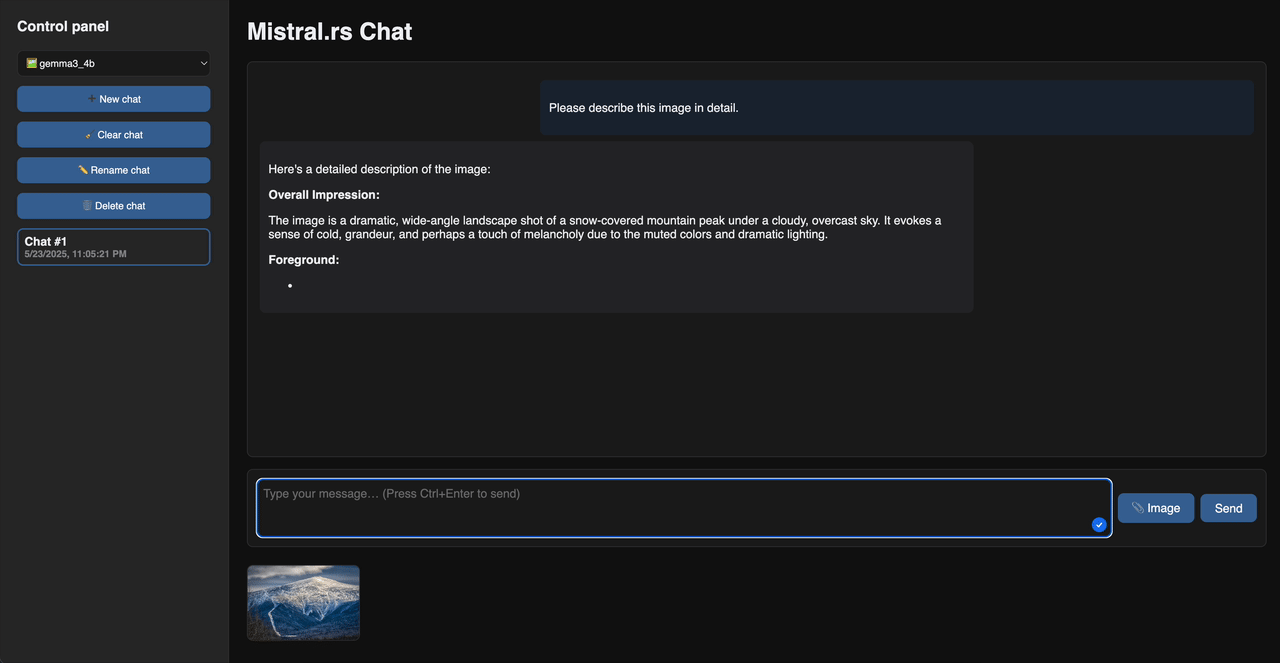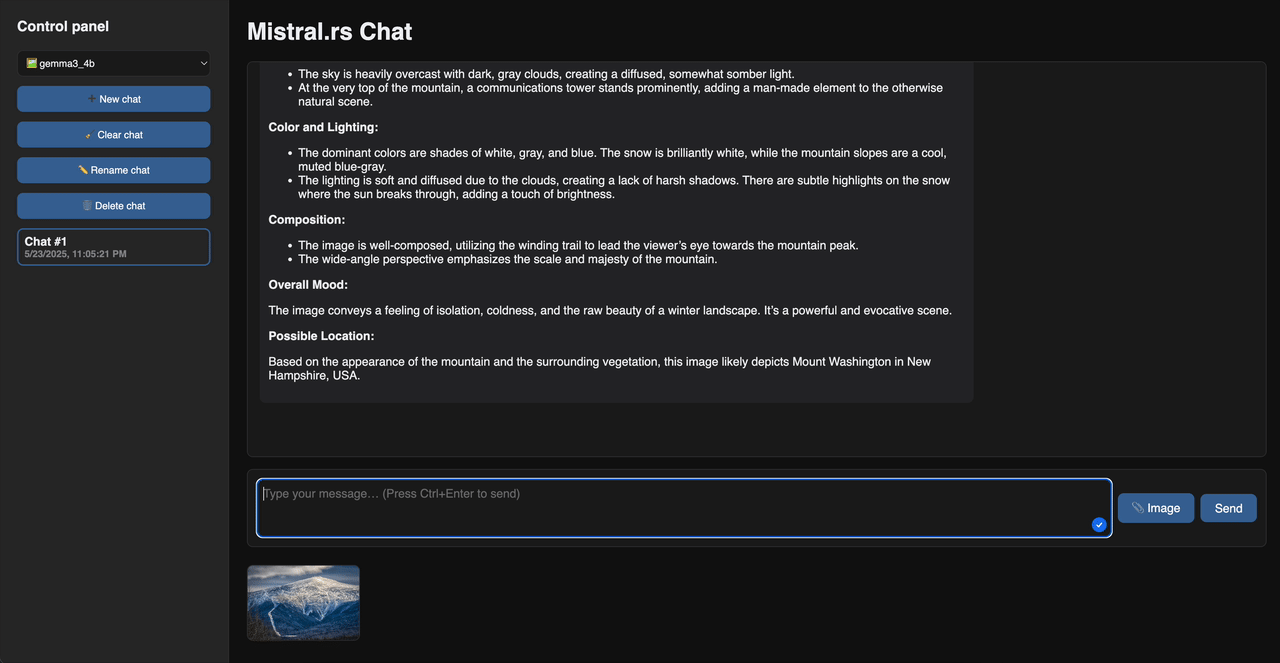
网页聊天演示
它为何如此快速
性能
- 默认在所有设备上支持连续批处理。
- CUDA 支持 FlashAttention V2/V3,Metal,多 GPU 张量并行
- PagedAttention 用于在 CUDA 或 Apple Silicon 上实现高吞吐量的连续批处理,支持前缀缓存(包括多模态)
量化 (完整文档)
- 对任何 Hugging Face 模型进行原位量化 (ISQ)
- 支持 GGUF (2-8 位)、GPTQ、AWQ、HQQ、FP8、BNB
- ⭐ 逐层拓扑:为每层微调量化以获得最佳质量/速度
- ⭐ 为你的硬件自动选择最快的量化方法
灵活性
- 支持 LoRA & X-LoRA 及权重合并
- AnyMoE:在任何基础模型上创建混合专家模型
- 多模型:运行时加载/卸载
智能体功能
- 集成工具调用,支持 Python/Rust 回调
- ⭐ 网络搜索集成
- ⭐ MCP 客户端:自动连接到外部工具
支持的模型
文本模型
- Granite 4.0 - SmolLM 3 - DeepSeek V3 - GPT-OSS - DeepSeek V2 - Qwen 3 Next - Qwen 3 MoE - Phi 3.5 MoE - Qwen 3 - GLM 4 - GLM-4.7-Flash - GLM-4.7 (MoE) - Gemma 2 - Qwen 2 - Starcoder 2 - Phi 3 - Mixtral - Phi 2 - Gemma - Llama - Mistral视觉模型
- Qwen 3.5 - Qwen 3.5 MoE - Qwen 3-VL - Qwen 3-VL MoE - Gemma 3n - Llama 4 - Gemma 3 - Mistral 3 - Phi 4 multimodal - Qwen 2.5-VL - MiniCPM-O - Llama 3.2 Vision - Qwen 2-VL - Idefics 3 - Idefics 2 - LLaVA Next - LLaVA - Phi 3V语音模型
- Voxtral (ASR/语音转文本) - Dia图像生成模型
- FLUX嵌入模型
- Embedding Gemma - Qwen 3 EmbeddingPython SDK
pip install mistralrs # 或 mistralrs-cuda, mistralrs-metal, mistralrs-mkl, mistralrs-accelerate
from mistralrs import Runner, Which, ChatCompletionRequest
runner = Runner(
which=Which.Plain(model_id="Qwen/Qwen3-4B"),
in_situ_quant="4",
)
res = runner.send_chat_completion_request(
ChatCompletionRequest(
model="default",
messages=[{"role": "user", "content": "Hello!"}],
max_tokens=256,
)
)
print(res.choices[0].message.content)
Python SDK | 安装 | 示例 | 使用指南
Rust SDK
cargo add mistralrs
use anyhow::Result;
use mistralrs::{IsqType, TextMessageRole, TextMessages, VisionModelBuilder};
#[tokio::main]
async fn main() -> Result<()> {
let model = VisionModelBuilder::new("google/gemma-3-4b-it")
.with_isq(IsqType::Q4K)
.with_logging()
.build()
.await?;
let messages = TextMessages::new().add_message(
TextMessageRole::User,
"Hello!",
);
let response = model.send_chat_request(messages).await?;
println!("{:?}", response.choices[0].message.content);
Ok(())
}
Docker
用于快速容器化部署:
docker pull ghcr.io/ericlbuehler/mistral.rs:latest
docker run --gpus all -p 1234:1234 ghcr.io/ericlbuehler/mistral.rs:latest \
serve -m Qwen/Qwen3-4B
对于生产环境,我们建议直接安装 CLI 以获得最大的灵活性。
文档
完整文档请参阅 文档网站。
快速链接:
- CLI 参考 - 所有命令和选项
- HTTP API - OpenAI 兼容的端点
- 量化 - ISQ、GGUF、GPTQ 等
- 设备映射 - 多 GPU 和 CPU 卸载
- MCP 集成 - MCP 集成文档
- 故障排除 - 常见问题及解决方案
- 配置 - 用于配置的环境变量
贡献
欢迎贡献!请提交 issue 讨论新功能或报告错误。如果你想添加新模型,请通过 issue 联系我们以便协调。
致谢
mistral.rs 与 Mistral AI 没有关联。