OA0 ›
代码 ›
Guidellm — 专注大模型压测与基准测试的工具链
Guidellm — 专注大模型压测与基准测试的工具链
zero · 2026-06-11 11:00:25 · 21 次点击 · 0 条评论
![]()
基于服务等级目标(SLO)的基准测试与评估平台,用于优化真实世界中的 LLM 推理




概览
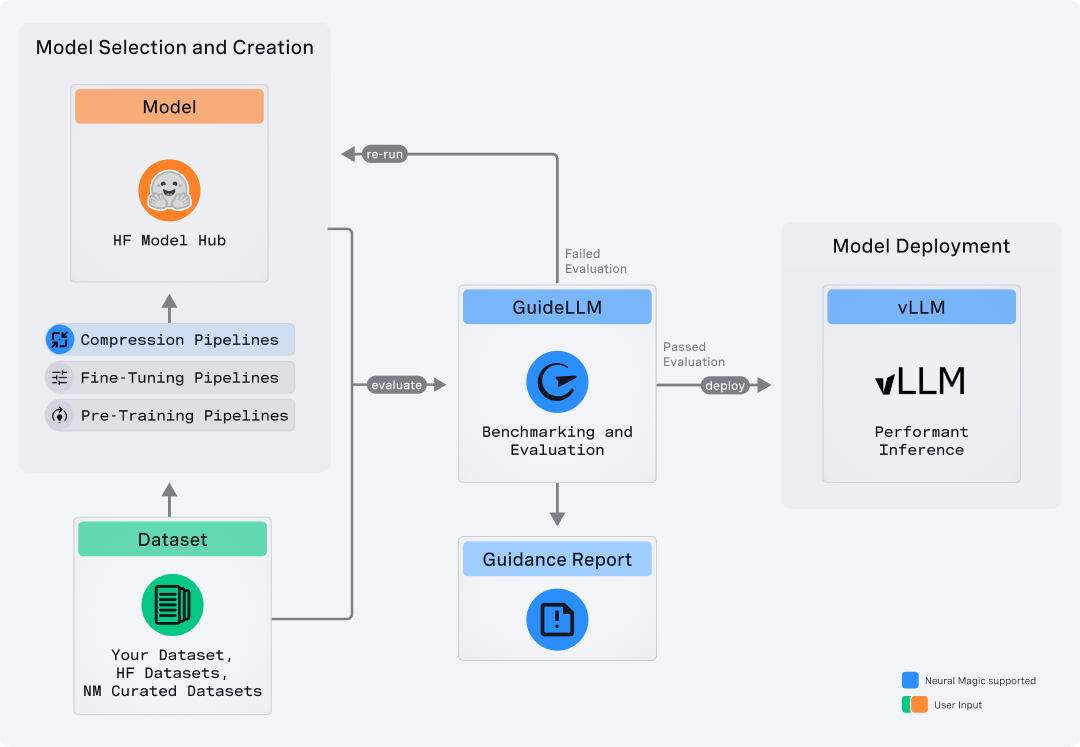
GuideLLM 是一个评估平台,用于衡量语言模型在实际工作负载和配置下的表现。它能够模拟与 OpenAI 兼容服务器和 vLLM 原生服务器的端到端交互,生成反映生产使用情况的工作负载模式,并输出详细报告,帮助团队了解系统行为、资源需求和运行限制。GuideLLM 支持真实和合成数据集、多模态输入以及灵活的执行配置,为工程和机器学习团队提供了一个一致的框架,用于评估模型行为、调优部署以及随系统演进而规划容量。
为什么选择 GuideLLM?
GuideLLM 能为团队提供在生产级环境中部署 LLM 时的性能、效率和可靠性的清晰图景。
- 捕获完整的延迟和词元级别统计数据,用于 SLO 驱动评估,包括 TTFT、ITL 和端到端行为的完整分布。
- 生成真实、可配置的流量模式,支持同步、并发和基于速率等多种模式,包括可重复的扫描,以确定安全运行范围。
- 支持真实和合成的多模态数据集,在同一个框架中实现受控的实验和生产级评估。
- 生成标准化的、可导出的报告,用于仪表盘、分析和回归追踪,确保跨团队和工作流的一致性。
- 通过多进程、多线程、异步执行以及灵活的 CLI/API ,提供高通量、可扩展的基准测试。
对比
许多工具只是对端点而非模型进行基准测试,并且忽略了 LLM 相关的关键细节。GuideLLM 专注于 LLM 特定的工作负载,测量 TTFT、ITL、输出分布以及由数据集驱动的变化。它通过使用标准的 Python 接口和 HuggingFace 数据集(而非自定义格式或仅用于研究的流程),很好地融入了日常工程任务。此外,它专为性能而生,支持高负载生成和精确调度,远超简单的脚本或示例基准测试。下表展示了本方法与其他工具的对比。
| 工具 | CLI | API | 高性能 | 完整指标 | 数据模态 | 数据来源 | 配置文件 | 后端 | 端点 | 输出类型 |
|---|---|---|---|---|---|---|---|---|---|---|
| GuideLLM | ✅ | ✅ | ✅ | ✅ | 文本、图像、音频、视频 | HuggingFace、文件、合成、自定义 | 同步、并发、吞吐量、恒定速率、泊松、扫描 | OpenAI 兼容 | /completions, /chat/completions, /audio/translation, /audio/transcription | console, json, csv, html |
| inference-perf | ✅ | ❌ | ✅ | ❌ | 文本 | 合成、特定数据集 | 并发、恒定速率、泊松、扫描 | OpenAI 兼容 | /completions, /chat/completions | json, png |
| genai-bench | ✅ | ❌ | ❌ | ❌ | 文本、图像、嵌入、重排序 | 合成、文件 | 并发 | OpenAI 兼容、托管云服务 | /chat/completions, /embeddings | console, xlsx, png |
| llm-perf | ❌ | ❌ | ✅ | ❌ | 文本 | 合成 | 并发 | OpenAI 兼容、托管云服务 | /chat/completions | json |
| ollama-benchmark | ✅ | ❌ | ❌ | ❌ | 文本 | 合成 | 同步 | Ollama | /completions | console, json |
| vllm/benchmarks | ✅ | ❌ | ❌ | ❌ | 文本 | 合成、特定数据集 | 同步、吞吐量、恒定速率、扫描 | OpenAI 兼容、vLLM API | /completions, /chat/completions | console, png |
最新动态
本节概述用户可用的最新功能,并指出当前开发方向。这有助于读者了解平台的演进和未来规划。
近期新增
- 全新重构的架构,支持大规模、高负载生成,并为更多后端、数据管道、负载生成调度、基准测试约束和输出格式提供了可扩展的接口。
- 新增多模态基准测试支持,涵盖图像、视频和音频工作负载,涉及聊天补全、转录和翻译 API。
- 更广泛的数据指标收集,包括为视觉、音频和文本输入提供更丰富的统计信息,如图像大小、音频长度、视频帧数和词级数据。
积极开发中
- 生成合成的多模态数据集,用于在图像、音频和视频方面的受控实验。
- 扩展前缀选项,用于测试系统提示和用户提示的变体。
- 多轮对话能力,用于基准测试聊天代理和对话系统。
- 投机性解码特定的视图和输出。
快速开始
本部分展示如何安装 GuideLLM、启动服务器并在几分钟内运行您的第一个基准测试。
安装 GuideLLM
安装前,请确保满足以下先决条件:
- 操作系统:Linux 或 MacOS
- Python:3.10 - 3.13
使用 pip 从 PyPi 安装最新的 GuideLLM 发行版:
pip install guidellm[recommended]
或从源码安装:
pip install git+https://github.com/vllm-project/guidellm.git
或从 ghcr.io/vllm-project/guidellm 运行最新容器:
podman run \
--rm -it \
-v "./results:/results:rw" \
-e GUIDELLM_TARGET=http://localhost:8000 \
-e GUIDELLM_PROFILE=sweep \
-e GUIDELLM_MAX_SECONDS=30 \
-e GUIDELLM_DATA="kind=synthetic_text,prompt_tokens=256,output_tokens=128" \
ghcr.io/vllm-project/guidellm:latest
启动推理服务器
启动任意 OpenAI 兼容端点。对于 vLLM:
vllm serve "neuralmagic/Meta-Llama-3.1-8B-Instruct-quantized.w4a16"
确认服务器正在 http://localhost:8000 运行。
运行您的第一个基准测试
运行一个扫描,以确定模型的最大性能和最大速率:
guidellm benchmark \
--target "http://localhost:8000" \
--profile kind=sweep \
--max-seconds 30 \
--data "kind=synthetic_text,prompt_tokens=256,output_tokens=128"
运行期间,您将看到进度更新和每个基准测试的摘要,如下所示:
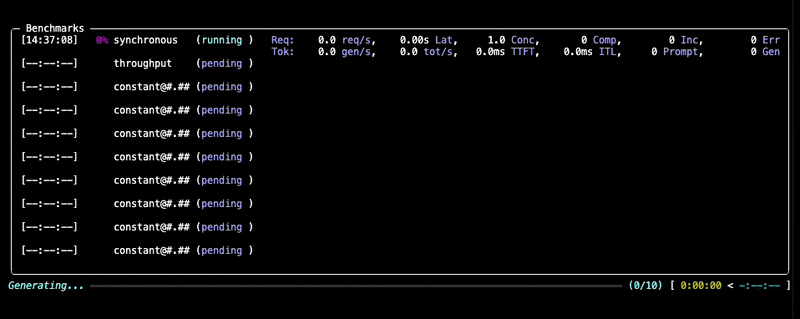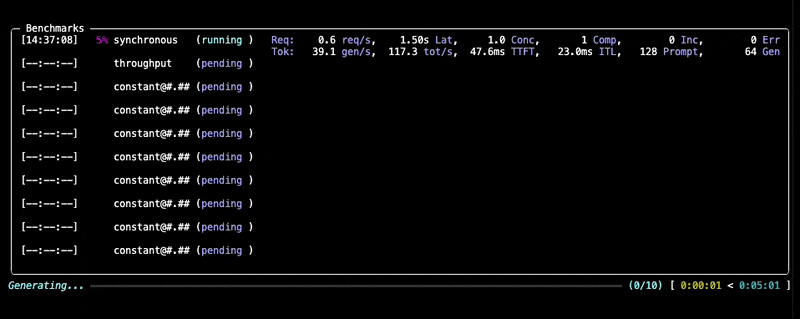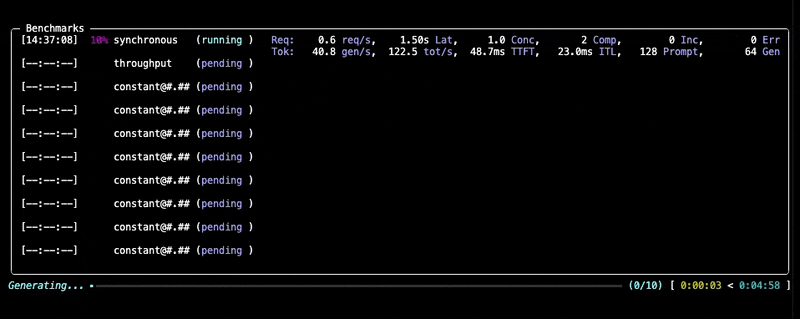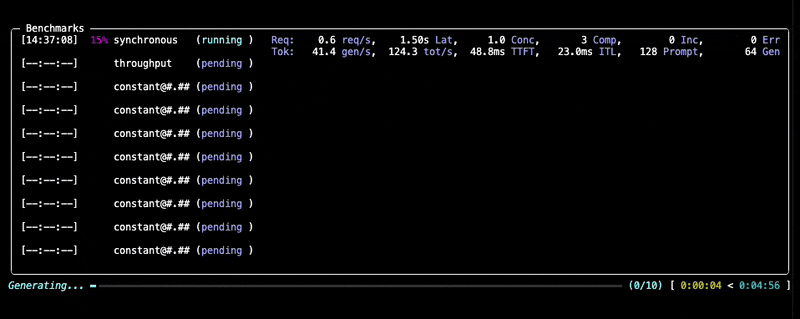
检查输出
基准测试完成后,GuideLLM 会将所有结果保存到您指定的输出目录(默认为当前目录)。您将在控制台看到打印出的摘要,以及一组包含完整运行结果的文件位置(.json, .csv, .html)。
下一节 输出文件与报告 将解释每个文件的内容,以及如何将它们用于分析、可视化和自动化。
输出文件与报告
运行快速入门基准测试后,GuideLLM 会将多个输出文件写入您指定的目录。每个文件专注于不同的分析层面,从快速的屏幕摘要到用于仪表盘和回归流程的完整结构化数据。
控制台输出
控制台为运行中的每个基准测试提供轻量级摘要和高级统计信息。这对于快速检查以确认服务器响应正确、负载扫描完成以及系统按预期运行非常有用。此外,输出表格可以使用 | 作为分隔符复制粘贴到电子表格软件中。其部分内容如下所示:
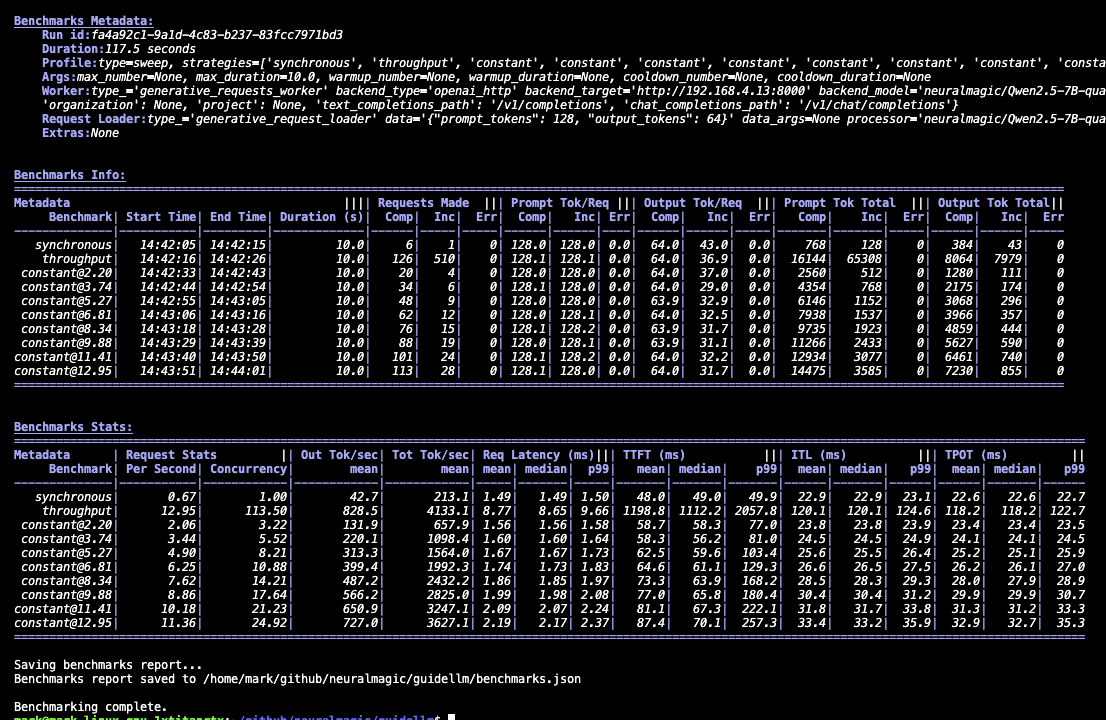
benchmarks.json
该文件是整个基准测试会话的权威记录。它包含配置、元数据、每个基准测试的统计信息以及包含单个请求时序的示例请求条目。可用于调试、深入分析或通过 GenerativeBenchmarksReport 加载到 Python 中。
或者,可以使用 --outputs yaml 参数生成此文件的 yaml 版本,以便于人类阅读,内容与 benchmarks.json 相同。
benchmarks.csv
该文件提供每个基准测试的紧凑表格视图,包含最常用于报告的字段——吞吐量、延迟百分位数、词元计数和速率信息。它可以干净地打开到电子表格和 BI 工具中,非常适合跨运行比较。
benchmarks.html
HTML 报告提供结果的可视化摘要,包括延迟分布、吞吐量行为和生成模式的图表。非常适合快速探索或与团队成员共享,而无需他们解析 JSON。
常见用例与配置
GuideLLM 支持广泛的 LLM 基准测试工作流。下面的示例展示了如何运行典型场景,并重点说明了最重要的参数。有关参数的完整列表、详情和选项,请运行 guidellm benchmark run --help。
负载模式
模拟不同的应用程序需要不同的流量模式。此示例演示了使用恒定配置文件进行基于速率的负载测试,速率为每秒10个请求,运行20秒,使用128个提示词元和256个输出词元的合成数据。
guidellm benchmark \
--target http://localhost:8000 \
--profile kind=constant \
--rate 10 \
--max-seconds 20 \
--data "kind=synthetic_text,prompt_tokens=128,output_tokens=256"
关键参数:
--profile: 定义流量模式 - GuideLLM 支持多种调度模式,包括synchronous(顺序请求)、concurrent(并行用户)、throughput(最大容量)、constant(固定请求/秒)、poisson(随机化请求/秒)或sweep(自动速率探索)。--rate: 数字速率值,其含义取决于配置文件 - 对于sweep,它是基准测试的数量;对于concurrent,它是同时请求数;对于constant/poisson,它是每秒请求数。--max-seconds: 每次基准测试运行的最大持续时间(秒)(也可以使用--max-requests按请求数量限制)。
数据集来源
GuideLLM 支持 HuggingFace 数据集、本地文件和合成数据。此示例从 HuggingFace 加载 CNN DailyMail 数据集,并将 article 列映射到提示,同时使用摘要词元计数列确定输出长度。
guidellm benchmark run \
--target http://localhost:8000 \
--data '{"kind": "huggingface", "source": "abisee/cnn_dailymail", "load_kwargs": {"name": "3.0.0"}}' \
--data-column-mapper '{"column_mappings": {"text_column": "article"}}'
关键参数:
--data: 数据源规范——对于合成数据,传递kind=synthetic_text,prompt_tokens=...,output_tokens=...;对于 HuggingFace 数据集,传递kind=huggingface,source=DATASET_ID(可选地使用load_kwargs配置数据集加载参数);对于本地文件,传递kind=json_file,path=.../kind=csv_file,path=.../kind=text_file,path=...;或用于轨迹重放文件的kind=trace_synthetic,path=...。可以多次指定,以使用多个数据源。--data-column-mapper: 用于数据集创建的 JSON 参数对象——常用于指定列映射,如text_column、output_tokens_count_column或 HuggingFace 数据集参数。--data-samples: 要从数据集中使用的样本数 - 使用-1(默认值)以动态生成所有样本,或指定正整数以限制样本数量。--processor: 用于生成合成数据的分词器或处理器名称 - 如果未提供且数据集需要,则会自动从模型加载;接受 HuggingFace 模型 ID 或本地路径。
请求类型与 API 目标
您可以对聊天补全、文本补全或其他支持的请求类型进行基准测试。此示例配置基准测试,使用自定义数据集文件测试聊天补全 API,GuideLLM 会自动将请求格式化为聊天补全模式。
guidellm benchmark \
--target http://localhost:8000 \
--request-type chat_completions \
--data "kind=json_file,path=path/to/data.json"
关键参数:
--request-type: 指定 API 端点格式 - 选项包括chat_completions(聊天 API 格式)、completions(文本补全格式)、audio_transcription(音频转录)和audio_translation(音频翻译)。
使用场景
内置场景将调度、数据集设置和请求格式化打包在一起,以标准化常见的测试模式。此示例使用预配置的聊天场景,其中包含适用于聊天模型评估的默认值,任何额外的 CLI 参数都将覆盖场景的设置。
guidellm benchmark --scenario chat --target http://localhost:8000
关键参数:
--scenario: 内置场景名称或自定义场景配置文件的路径 - 内置选项包括针对常见用例的预配置测试模式;同时传递的 CLI 选项将覆盖场景的默认设置。
基准测试控制
预热、冷却和最大限制有助于确保稳定、可重复的测量。此示例运行一个并发基准测试,包含16个并行请求,使用10%的预热和冷却期间来排除初始化和关闭的影响,同时限制测试在发生超过5个错误时停止。
guidellm benchmark \
--target http://localhost:8000 \
--profile kind=concurrent \
--rate 16 \
--warmup 0.1 \
--cooldown 0.1 \
--max-errors 5 \
--data "kind=synthetic_text,prompt_tokens=256,output_tokens=128" \
--detect-saturation
关键参数:
--warmup: 预热规范 - 0到1之间的值表示占总请求/时间的百分比,≥1的值表示绝对请求数或时间单位。--cooldown: 冷却规范 - 格式与预热相同,从分析中排除基准测试的最终部分,以避免关闭效应。--max-seconds: 每次基准测试在自动终止前的最大持续时间(秒)。--max-requests: 每次基准测试在自动终止前的最大请求数。--max-errors: 最大个别错误数,超过后完全停止基准测试。--data: 用于基准测试的数据——256个输入和128个输出词元的合成数据。--detect-saturation: 启用过饱和检测,以在模型过饱和时自动停止基准测试(另请参阅--over-saturation以进行更高级的控制)。
开发与贡献
有兴趣扩展 GuideLLM 的开发者可以使用项目既定的开发工作流。本地设置、环境激活和测试说明见 DEVELOPING.md。该指南解释了如何在开发期间运行基准测试套件、验证更改以及使用 CLI 或 API。贡献标准记录在 CONTRIBUTING.md中,包括编码规范、提交结构和审查指南。这些标准有助于在平台发展过程中保持稳定性。CODE_OF_CONDUCT.md 概述了在所有项目空间内进行尊重和建设性参与的期望。对于希望获得更深入参考资料的贡献者,文档涵盖了安装、后端、数据集、指标、输出类型和架构。在添加新的后端、请求类型或数据集成时,回顾这些主题会很有用。发行说明和变更日志可从 GitHub Releases 页面链接获得,并为正在进行的工作提供历史背景。
文档
完整的文档提供了本 README 中未包含的详细信息。它包括安装步骤、后端配置、数据集处理、指标定义、输出格式、教程和架构概述。这些参考资料可以帮助您更深入地探索平台,或将其集成到现有工作流中。
以下是一些值得关注的文档:
- 安装指南 - 本指南提供安装 GuideLLM 的分步说明,包括先决条件和设置技巧。
- 后端指南 - 所支持后端的全面概述以及如何设置它们以与 GuideLLM 一起使用。
- 数据/数据集指南 - 关于受支持数据集的信息,包括如何将它们用于基准测试。
- 指标指南 - GuideLLM 中使用的指标的详细说明,包括定义和如何解读。
- 输出指南 - GuideLLM 支持的不同输出格式的信息以及如何使用它们。
- 架构概览 - 对 GuideLLM 的设计、组件及其交互方式的详细说明。
许可证
GuideLLM 采用 Apache License 2.0 许可。
引用
如果您在研究或项目中觉得 GuideLLM 有帮助,请考虑引用它:
@misc{guidellm2024,
title={GuideLLM: Scalable Inference and Optimization for Large Language Models},
author={Neural Magic, Inc.},
year={2024},
howpublished={\url{https://github.com/vllm-project/guidellm}},
}