社区运行状况
| 注册会员 | 1205 |
| 主题 | 846 |
| 模型 | 3026 |
| 技能包 | 13874 |
| 数据集 | 1047 |
| 论文 | 380 |
| 开源项目 | 602 |
LiveBench 发布说明
一项具有挑战性、无污染的 LLM 基准评测
作者:Colin White*1、Samuel Dooley*1、Manley Roberts*1、Arka Pal*1、Ben Feuer2、Siddhartha Jain3、Ravid Shwartz-Ziv2、Neel Jain4、Khalid Saifullah4、Siddartha Naidu1、Chinmay Hegde2、Yann LeCun2、Tom Goldstein4、Willie Neiswanger5、Micah Goldblum2
1Abacus.AI,2NYU,3Nvidia,4UMD,5USC。本研究由 Abacus.AI 赞助。
简介
在此我们介绍 LiveBench:一项面向大语言模型(LLM)的基准评测,在设计上兼顾测试集污染防控与客观评估。
LiveBench 具有以下特点:
- 通过每月发布新题目,并采用基于近期发布的数据集、arXiv 论文、新闻文章和 IMDb 电影简介的题目,LiveBench 旨在降低潜在污染。
- 每道题都有可验证的客观标准答案,使难题能够被准确、自动评分,而无需使用 LLM 作为评判。
- LiveBench 目前包含 6 大类共 17 项任务,我们将持续发布新的、更具挑战性的任务。
我们于今日发布首批 960 道题,并计划每月发布新题集。通过这种方式,我们希望 LiveBench 能够避免污染,因为每次发布都会包含全新题目。
除污染问题外,LiveBench 通过仅包含具有客观答案的题目,避免了 LLM 评判的缺陷。尽管 LLM 评判以及众包提示与评估有很多优点,它们也会引入显著偏差,并在评判难题答案时完全失效。例如,我们在论文中表明,对于具有挑战性的推理与数学题,GPT-4-Turbo 的通过/不通过评判错误率最高可达 46%。
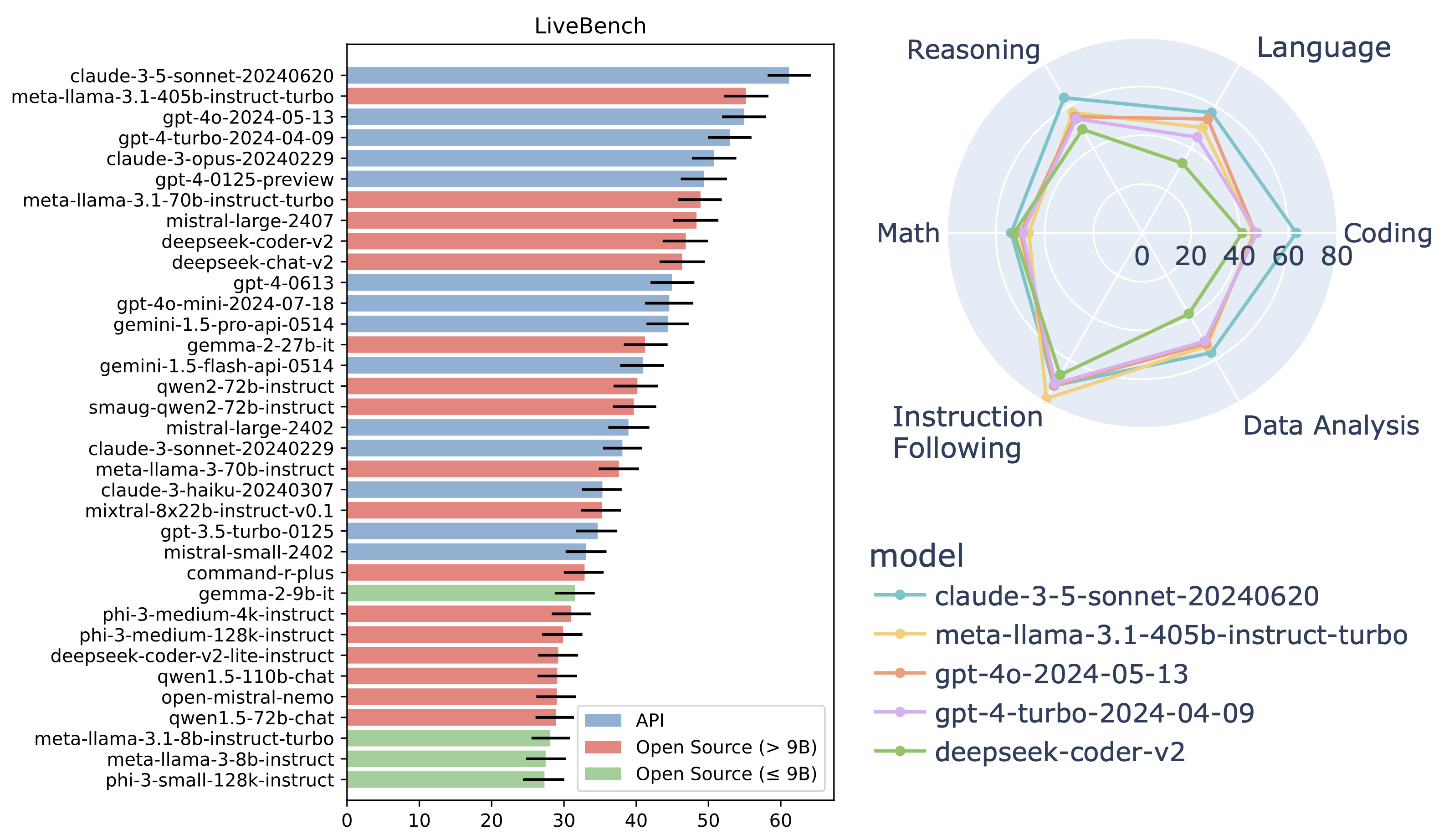
LiveBench 目前评估多款主流闭源模型以及数十个开放权重模型(规模从 0.5B 到 70B 不等)。LiveBench 题目难度较高;例如,GPT-4-Turbo 在 LiveBench 上的整体准确率约为 50%。此外,在每月更新中,我们将持续发布新任务和更难版本,以便在 LLM 能力提升后仍能有效区分其水平。
LiveBench 概览
LiveBench 目前包含 6 大类共 17 项任务:推理、数据分析、数学、编程、语言理解与指令遵循。每项任务属于以下两种类型之一:
- 使用持续更新信息源出题的任务,例如基于近期 Kaggle 数据集的数据分析,或修正近期 arXiv 摘要中的笔误;
- 对现有基准任务进行更具挑战性或更多样化改版的任务,例如来自 AMPS、Big-Bench Hard、IFEval 或 bAbI 的题目。
LiveBench 包含的类别与任务如下:
数学:过去 12 个月内高中数学竞赛题目(AMC12、AIME、USAMO、IMO、SMC),以及AMPS题目的更难版本。
编程:来自 Leetcode 与 AtCoder 的两项任务(经由LiveCodeBench):代码生成与一项新颖的代码补全任务。
推理:Big-Bench Hard 中「谎言网络」的更难版本,以及斑马谜题。
语言理解:三项任务,包括Connections 单词谜题、纠错任务,以及基于 IMDb 与维基百科上近期电影的剧情梗概打乱重组任务。
指令遵循:四项任务,对《卫报》近期新闻进行复述、简化、摘要或生成故事,并满足一项或多项约束(如字数限制或在回答中包含特定要素)。
数据分析:三项任务,均使用来自 Kaggle 与 Socrata 的近期数据集:表格重格式化(支持 JSON、JSONL、Markdown、CSV、TSV、HTML)、预测两表可连接列、预测数据列的正确类型标注。
设计动机
创建 LiveBench 的目标是确保题目不易发生污染,并能简便、准确、公平地得到评估。
许多 LLM 基准很容易被污染,因为现代 LLM 的训练数据中包含大量互联网内容。这对 LLM 评估构成问题:若模型在训练中见过某基准的题目,其在该基准上的表现会被人为抬高,即被污染。
例如,近期研究表明,LLM 在 Codeforces 上的表现在其训练数据截止日之后大幅下降,而在截止日之前,表现与题目在 GitHub 上的出现次数高度相关。同样,针对经典数学数据集 GSM8K 的近期手工变体显示,多个模型已对该基准过拟合。
确保我们评估 LLM 答案的方式公平且无偏也很重要。在防污染基准中,目前主要有两种做法:以 LLM 为评判(LLM-as-a-judge)和以人类为评判(Humans-as-a-judge)。
以 LLM 为评判:LLM 评判速度快、成本相对低,其最大优势是能评判开放式问题、指令遵循题和聊天机器人。但 LLM 评判存在明显不足:(1)LLM 会偏向自己的答案,通常只有 GPT-4 与 Claude-3-Opus 被用作评判,而二者均偏向自身输出;(2)对不同模型的方差与偏好存在明显差异,且 GPT-4 即便在 temperature 0 下自身评判也有方差;(3)对有标准答案的题目,LLM 评判会出错,例如 Arena-Hard 第 2 题要求写 C++ 程序判断给定字符串能否通过交换两个字母变为「abc」,GPT-4 会错误地判定自己的正确解答为错误。我们在下文中给出更多证据。
以人类为评判:人类评估能很好反映大众偏好,但存在诸多劣势:(1)人工评判劳动密集,尤其对复杂数学积分、编程题或长上下文推理题;(2)对这些题目人类也常会出错;(3)人与人之间差异较大;(4)人类还会基于正确性以外的维度评估,例如偏好特定长度、格式或正式程度的输出。
与上述方式不同,LiveBench 采用客观的、基于标准答案的评判来评估每道题。
客观标准答案评判将 LLM 输出与事先确定的标准答案比对。这种方式在时间和成本上易于计分,并避免了上述在偏差、错误与评判方差上的问题。其局限在于某些类型的问题没有标准答案(例如「写一份夏威夷旅行指南」)。尽管如此,这只限制可被评估的题目类型,不影响能以这种方式评判的题目的有效性。
表:在以 LLM 为评判时,在挑战性数学(AMC、AIME、SMC)与推理(斑马谜题)任务上的错误率。评判模型为 GPT-4-Turbo,被评判的是 GPT-4-Turbo 与 Claude-3-Opus 的输出。在所有任务上错误率都高得惊人,说明 LLM 对这些任务并非可靠评判。
| AMC12 2024 | AIME 2024 | SMC 2023 | 斑马谜题 | |
|---|---|---|---|---|
| GPT-4-Turbo | 0.380 | 0.214 | 0.353 | 0.420 |
| Claude-3-Opus | 0.388 | 0.103 | 0.294 | 0.460 |
由上可见,在这些任务上,采用客观标准答案评判优于 LLM 评判。在这四项任务中,客观评判可做到完全正确,而 LLM 评判的错误率远高于可接受水平,说明 LLM 不适合作为高难度数学与逻辑任务的评判。
与其他基准的对比
我们将 LiveBench 与当前主流 LLM 基准进行了对比:ChatBot Arena 与 Arena-Hard。整体趋势较为一致,但部分模型在一个基准上明显强于另一个,这可能反映了 LLM 评判的某些弊端。
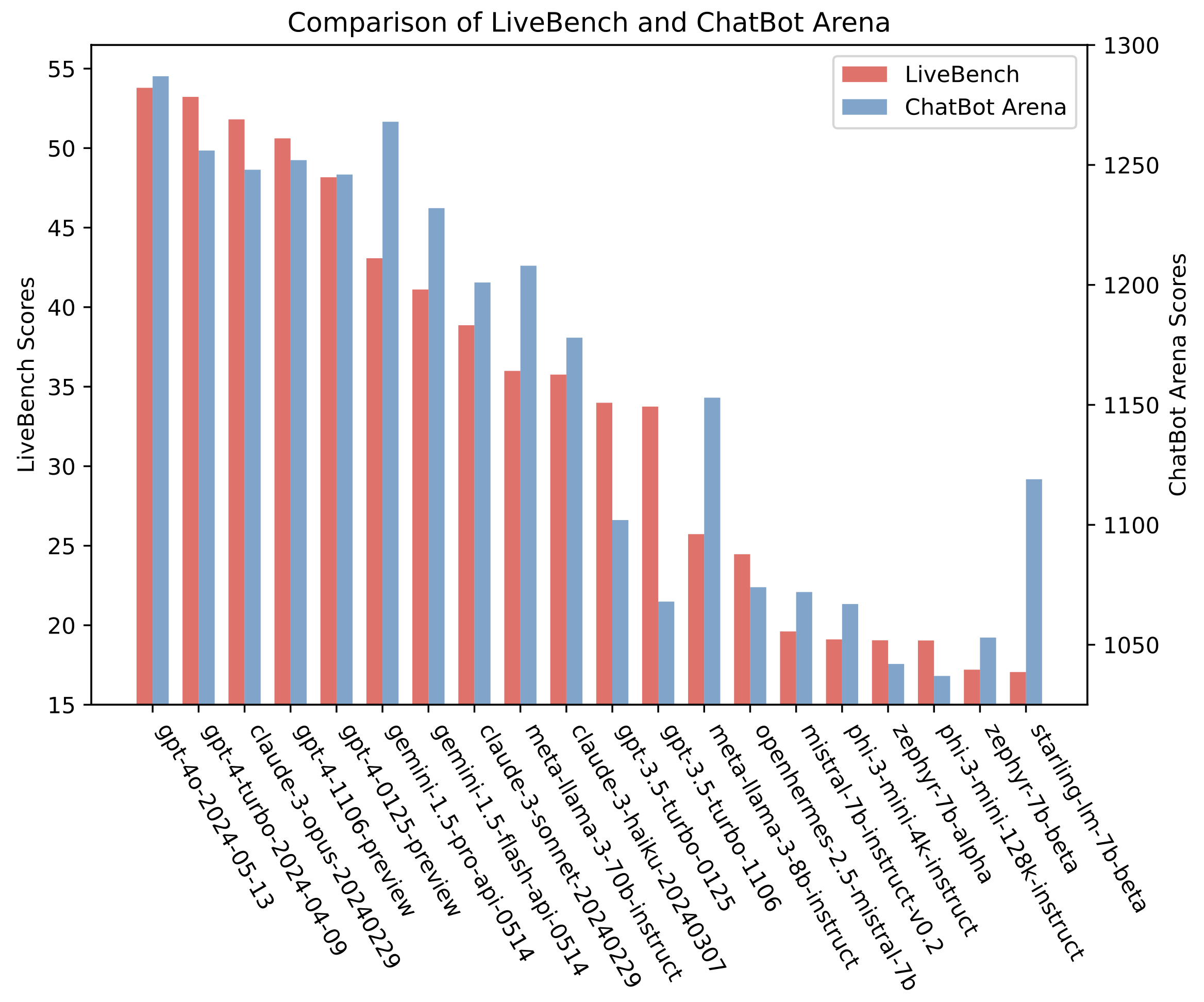
LiveBench 与 ChatBot Arena 同模型得分对比
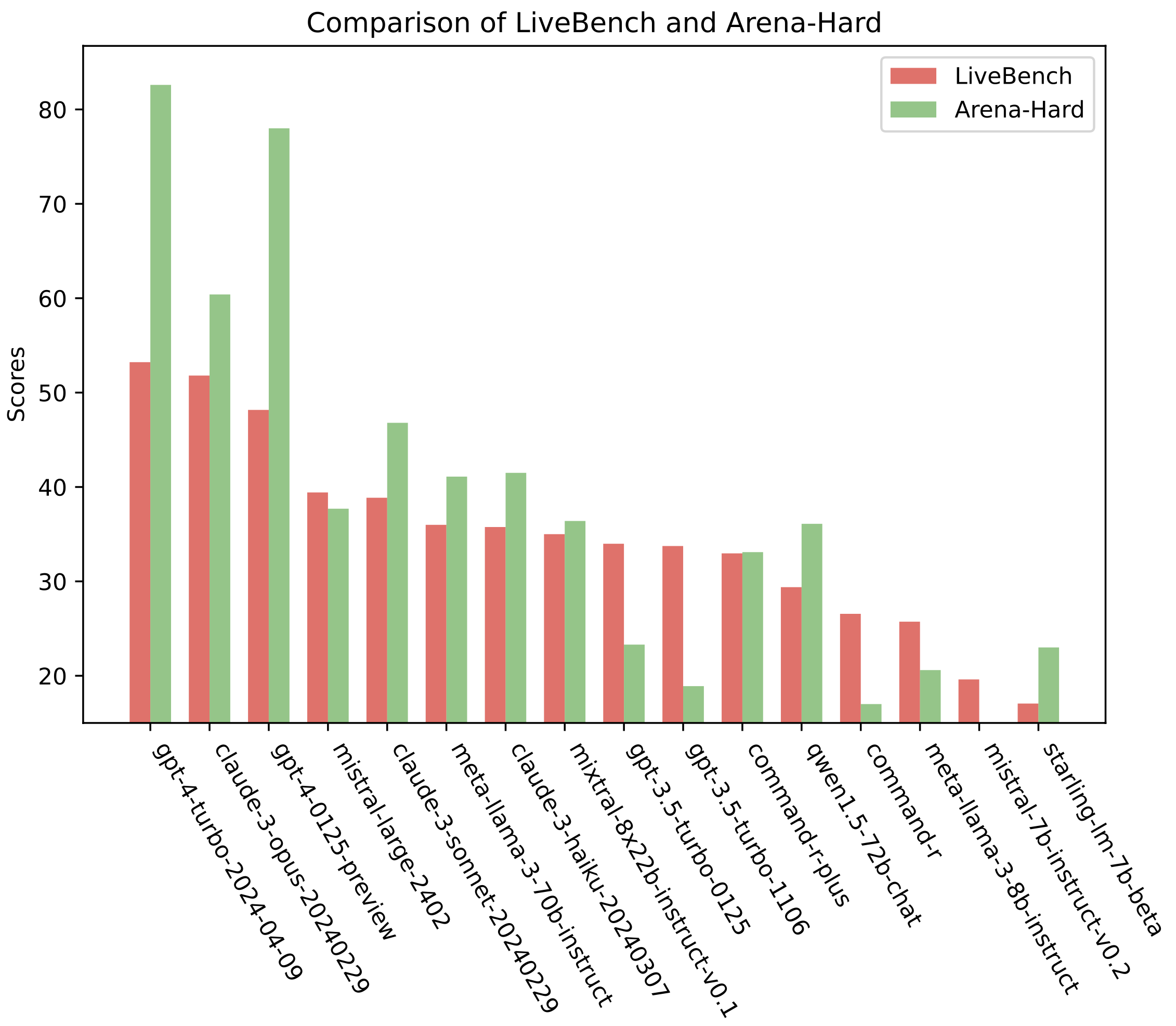
LiveBench 与 Arena-Hard 同模型得分对比。GPT-4 系列在 Arena-Hard 上相对 LiveBench 明显更好,可能与使用 GPT-4 作为评判的已知偏差有关。
LiveBench 与 ChatBot Arena 的模型得分 Pearson 相关系数为 0.90,与 Arena-Hard 为 0.89。
从相关性与图表可以看出,LiveBench 总体趋势与二者相似,但部分模型在不同基准上表现差异明显。例如,gpt-4-0125-preview 与 gpt-4-turbo-2024-04-09 在 Arena-Hard 上相对 LiveBench 明显更好——很可能源于使用 GPT-4 自身作为 LLM 评判的已知偏差。
我们对 LiveBench 的未来充满期待,并希望与研究者合作扩展题目、任务列表、类别与评估模型。若您希望参与或有任何问题,欢迎联系。
BibTeX
@inproceedings{livebench,
title={LiveBench: A Challenging, Contamination-Free {LLM} Benchmark},
author={Colin White and Samuel Dooley and Manley Roberts and Arka Pal and Benjamin Feuer and Siddhartha Jain and Ravid Shwartz-Ziv and Neel Jain and Khalid Saifullah and Sreemanti Dey and Shubh-Agrawal and Sandeep Singh Sandha and Siddartha Venkat Naidu and Chinmay Hegde and Yann LeCun and Tom Goldstein and Willie Neiswanger and Micah Goldblum},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
}